Firestore設計:サブコレ・正規化・インデックス最適化:アウトライン20章
ゴールは「どんな形で保存すべき?」を自分で判断できる状態にすることです💪✨(サブコレ/正規化/インデックス/集計/型安全CRUDまで)
このカテゴリで作る成果物(最終ゴール)🎯
「日報 / 記事 / コメント」3階層を題材にして、次を完成させます👇📝
- Firestoreのデータ構造(コレクション設計)
- よく使う画面(一覧/詳細/コメント欄)を想定したクエリ設計🔎
- インデックスを“意図して”作れる状態🛠️(遅い→なぜ?→どう直す?)
- 集計(いいね数/コメント数/ランキング)を安全に運用できる形🥇
- TypeScriptで**型安全CRUD(DTO/Converter)**を整備🧱(withConverter)
- AI(Firebase AI Logic / Genkit / Antigravity / Gemini CLI)で設計レビューと実装を加速🤖⚡ ※AI機能はApp Checkやレート制限も絡むので、設計で“事故りにくい形”に寄せます💡 (Firebase)
20章アウトライン(読む→手を動かす→ミニ課題→チェック)📚✨
第1章:Firestore設計って何を決めるの?(最短で地図を作る)🗺️
- 読む:設計で決めるのは「画面に必要な取り出し方」から逆算😄
- 手を動かす:日報/記事/コメントの画面一覧を紙に書く📝
- ミニ課題:“必要なクエリ”を10個書き出す(例:記事一覧/自分の投稿/最新コメント…)
- チェック:クエリが決まると保存形が決まる感覚が出たらOK✅
第2章:エンティティ分解(User / Report / Post / Comment)🧩
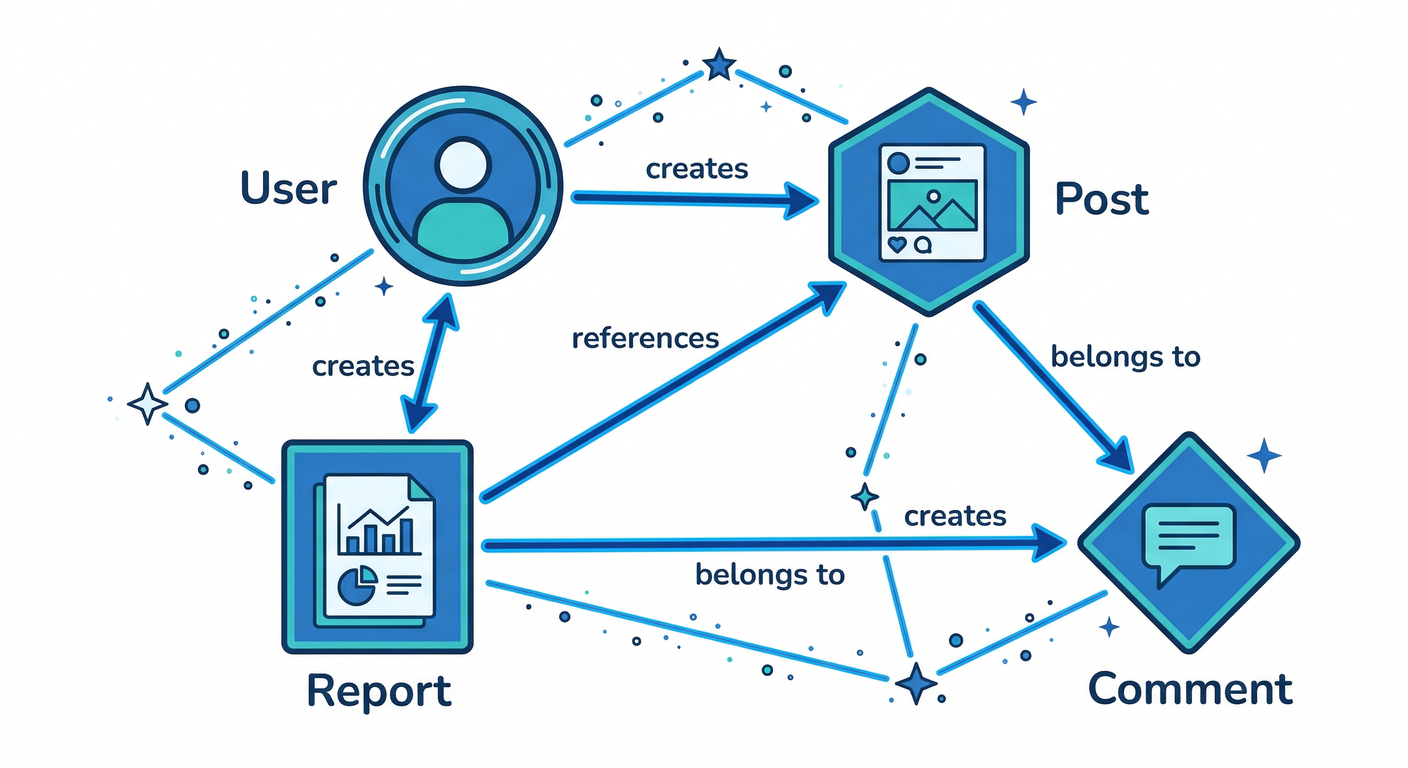
- 読む:「どの単位がドキュメント?」を決める
- 手を動かす:各エンティティの必須フィールドを列挙
- ミニ課題:**“編集される頻度”**を各フィールドにメモ(後で非正規化判断に使う)
- チェック:頻繁に更新される物が1つのドキュメントに集まりすぎてない?👀
第3章:ID設計(自動ID vs 意味のあるID)🆔
- 読む:IDは“検索”じゃなく“参照”を強くする道具
- 手を動かす:
users/{uid}にする?別IDにする?を決める - ミニ課題:URLに載せるID/載せないIDを分ける
- チェック:推測されるIDにしない(事故防止)✅
第4章:サブコレクションの使いどころ(親子関係に強い)🧩
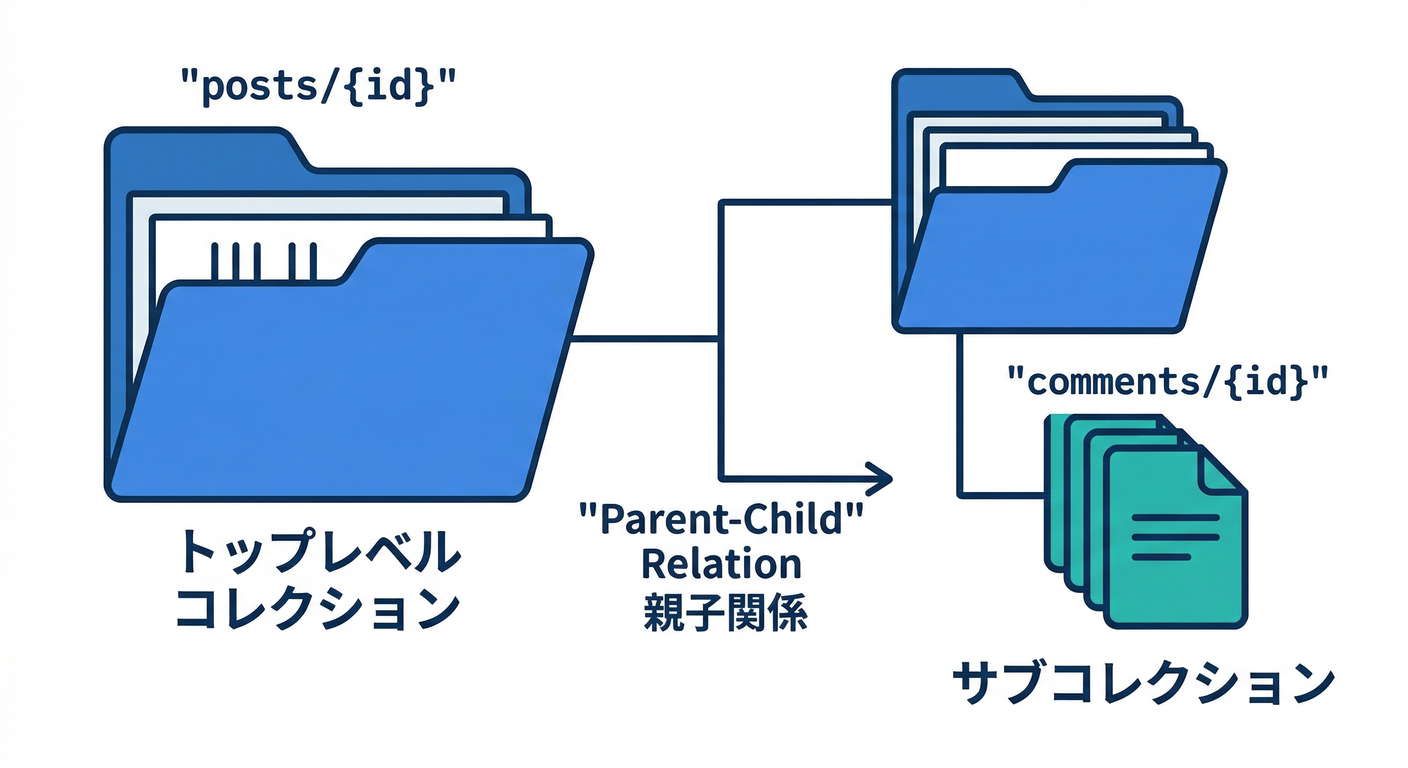
- 読む:サブコレは「親にぶら下がる大量データ」に強い💪
- 手を動かす:
posts/{postId}/comments/{commentId}を作る案を考える - ミニ課題:**コメントはサブコレ?トップレベル?**両案を作る
- チェック:同じID名のサブコレならコレクショングループクエリも使えるのを覚える✅ (Firebase)
第5章:サブコレの落とし穴(削除・移動・集計)💥
- 読む:サブコレはまとめて消しにくい(運用で詰まりがち)😇 (Google Cloud Documentation)
- 手を動かす:削除方針(論理削除/TTL/手動クリーンアップ)を選ぶ
- ミニ課題:「記事削除時にコメントもどう扱う?」を決める
- チェック:削除=データ設計の一部、になってればOK✅
第6章:正規化 vs 非正規化(Firestore流の割り切り)⚖️
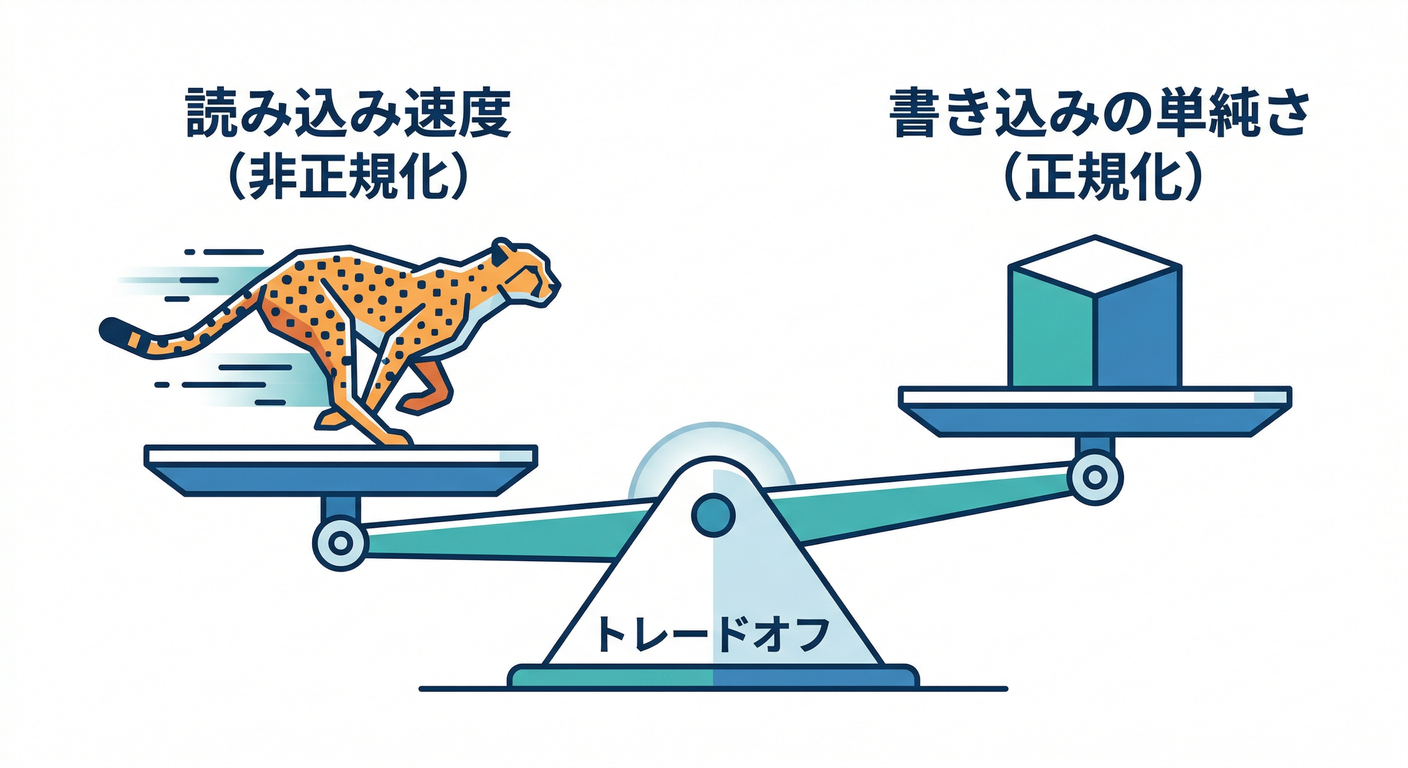
- 読む:Firestoreは“JOINしない前提”で考えるのがコツ😄
- 手を動かす:記事に表示したい「投稿者名/アイコン」をどう持つか考える
- ミニ課題:**“表示に必要な情報は複製OK”**のラインを決める
- チェック:更新頻度が低い物は複製しやすい、が腹落ち✅
第7章:参照の持ち方(id文字列 vs DocumentReference)🔗
- 読む:参照は「読みやすさ」「移植しやすさ」「型」に影響
- 手を動かす:
authorId: string/authorRefどちらにするか決める - ミニ課題:参照先が消えた時の表示(“退会ユーザー”)を決める
- チェック:参照切れ時に落ちないUI設計になってる✅
第8章:一覧に強い設計(“並べ替え”から逆算)📜
- 読む:一覧画面は
orderBy + limitを前提にすると楽✨ - 手を動かす:記事一覧のソートキー(
createdAtなど)を決める - ミニ課題:“同点が出たときの並び”(第2キー)も決める
- チェック:安定ソートの発想が出たらOK✅
第9章:ホットスポットと書き込み衝突(地味に重要)🔥
- 読む:1ドキュメントに書き込み集中すると詰まることがある😵
- 手を動かす:コメント数やいいね数を「直書き」する危険を理解
- ミニ課題:“集中しそうな更新”を3つ挙げ、対策メモ
- チェック:アクセス増を想像して「1点集中を避ける」意識が出たらOK✅ (Firebase)
第10章:集計の全体像(いつ計算する?いつ保存する?)🧮
- 読む:集計は「その場で数える」or「保存しておく」の二択
- 手を動かす:コメント数/いいね数/ランキングを分類する
- ミニ課題:「リアルタイム性が必要?」を各集計に付ける
- チェック:集計ごとに方針が違ってOK、が理解できたら✅
第11章:Aggregation Queries(Count / Sum / Avg)で“その場集計”📊
- 読む:Firestoreは集計クエリも用意されてる(使い所を知る)✨ (Google Cloud)
- 手を動かす:一覧画面で「件数だけ知りたい」ケースを想定
- ミニ課題:「件数表示」を集計クエリでやる案を設計
- チェック:集計の“読みコスト”の感覚が出たらOK✅
第12章:分散カウンタ(シャーディング)で“書き込み集計”を守る🧱
- 読む:頻繁更新カウンタは分散カウンタが定番🥇 (Firebase)
- 手を動かす:いいね数を「shards」方式で持つ案を作る
- ミニ課題:shard数の決め方(最初は少なく→増やす)をメモ
- チェック:高頻度更新=分散の発想が出ればOK✅
第13章:ランキング設計(Top Nを気持ちよく出す)🥇
- 読む:ランキングは「並べ替えできるスコア」を持つのが基本
- 手を動かす:
score/likesCount/hotScoreなどを設計 - ミニ課題:日次/週次ランキングの保存場所を決める
- チェック:ランキングは“別コレクション化”してOKと思えたら✅
第14章:インデックスの超基本(何が速くなる?何が増える?)🧭
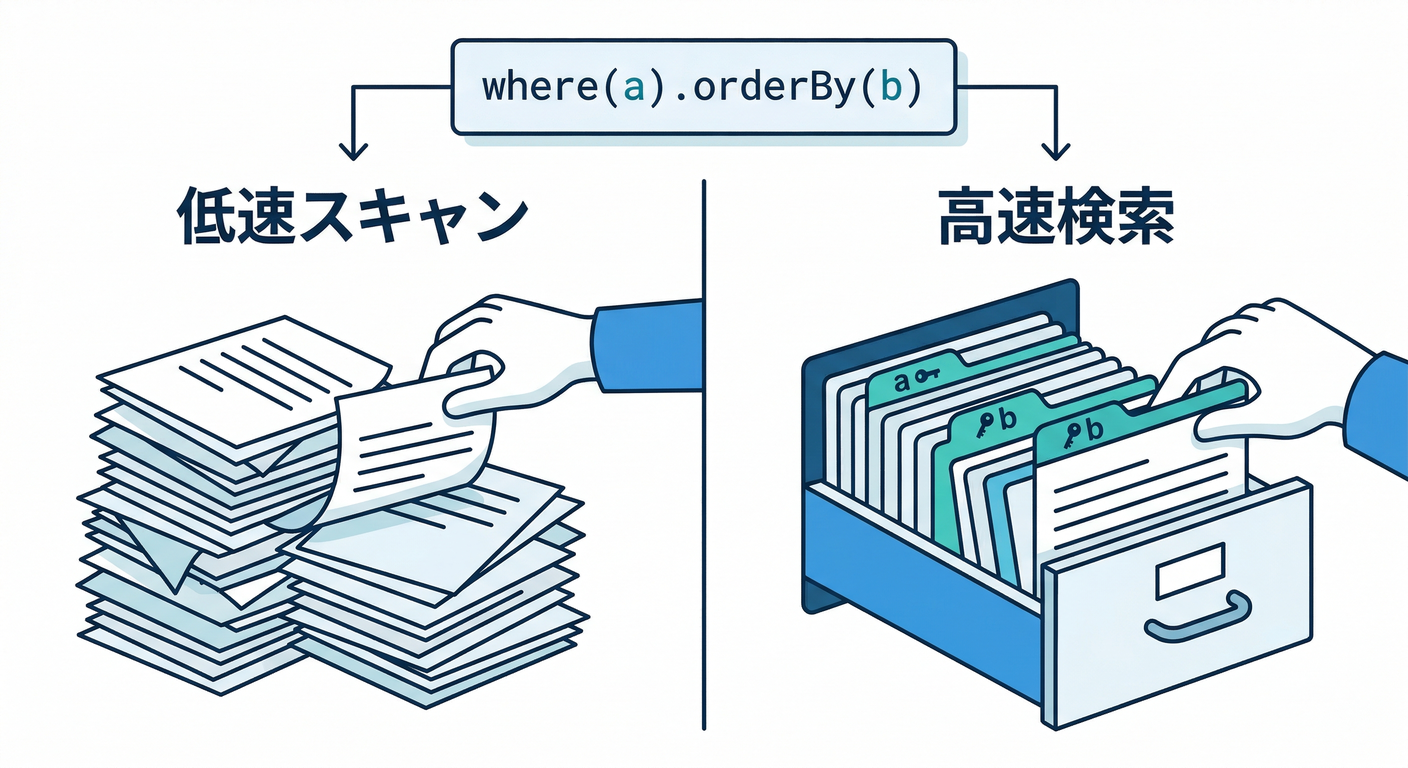
- 読む:Firestoreはインデックスが命!複合インデックスも理解🛠️ (Firebase)
- 手を動かす:自分のクエリ10個に「必要そうなインデックス」を印をつける
- ミニ課題:配列系(
array-contains)を使う場所を洗い出す - チェック:配列フィールドは複合インデックスで制約があるのを覚えたらOK✅ (Firebase)
第15章:インデックス実践(エラー→作成→改善の流れ)🔧
- 読む:“遅い/失敗”はコンソールのインデックス画面で直していく
- 手を動かす:わざと
where + orderByを組み合わせて「必要インデックス」を体験 - ミニ課題:インデックス作成の判断フローを1枚にまとめる
- チェック:エラー文を見て落ち着けるようになったらOK✅
第16章:orderBy の罠(存在しないフィールドは落ちる)🕳️
- 読む:
orderBy()はそのフィールドが無いドキュメントを結果から外す⚠️ (Firebase) - 手を動かす:
createdAtを必ず入れる設計にする - ミニ課題:必須フィールドを「作成時に自動で埋める」方針を決める
- チェック:検索の安定性=設計で作る、が理解できたら✅
第17章:複数範囲クエリと制約(2026の重要ポイント)📏
- 読む:複数フィールドの範囲/不等号も使えるが、制限がある🧠 (Firebase)
- 手を動かす:「検索フィルタUI」を想定して、許される組み合わせを整理
- ミニ課題:やりたい検索が無理なら“検索用フィールド”を作る案を考える
- チェック:「クエリが無理なら保存形を変える」が出たらOK✅
第18章:ページング設計(無限スクロールの作法)📜
- 読む:ページングは
limit + cursor(startAfter等)の安定運用が大事 - 手を動かす:一覧クエリの「次ページ条件」を設計
- ミニ課題:並び順が変わるとページングが壊れる例を想像して対策
- チェック:ソートキーは必須、が腹落ちしたら✅
第19章:TypeScriptで“型安全CRUD”(DTO/Converter/ガード)🧱✨
- 読む:Firestoreの型は“Converterで守る”のが王道💪(
withConverter) (Firebase) - 手を動かす:
PostDTO / CommentDTOを作り、読み書きにConverterを挟む - ミニ課題:**「Firestoreに保存する形」と「UIで使う形」**を分ける(DTOを作る)
- チェック:
doc.data()に型が付いて気持ちよくなったら勝ち✅
第20章:整合性を“サーバー側”で守る(Functions / Cloud Run / AI)⚙️🤖
-
読む:集計や整合性は、クライアント任せにしないのが安全😇
-
手を動かす:
- Node.jsのFunctions(2nd gen)で「コメント追加→コメント数更新」を設計
- 本日時点で Node.js 22 / 20 が選べる(Firebase Functionsのランタイム) (Firebase)
- Pythonも python311 / python310 のランタイム指定が可能(同ページ) (Firebase)
- .NETは「Firebase Functions」ではなく、必要なら Cloud Run functions 側(.NETも対象)という整理にする (Google Cloud Documentation)
-
ミニ課題:AI生成結果をFirestoreに保存する「監査ログ」設計
- 例:
aiLogsに{ model, promptHash, createdAt, userId, action }など - Firebase AI LogicはクライアントSDK+App Check+レート制限などの考え方がある (Firebase)
- 例:
-
チェック:クライアント改ざんでも“壊れにくい設計”になったらOK✅
AIで設計が爆速になる「使い方テンプレ」🤖⚡(Antigravity / Gemini CLI)

- Antigravityは“エージェントが計画→実行→検証”まで回す思想の開発環境(Mission Control的な使い方) (Google Codelabs)
- Gemini CLIはターミナルで動くAIエージェント(ReActで作業を進める) (Google for Developers)
すぐ使える依頼例(コピペ用)📎
-
スキーマ案を2〜3パターン出して比較
- 「記事/コメント/ユーザーをFirestoreで設計。サブコレ案とトップレベル案を比較して、想定クエリと必要インデックスも列挙して」
-
インデックスの抜けを洗う
- 「このクエリ一覧に必要な複合インデックスを推定して、運用で困るポイントも教えて」
-
DTO/Converter雛形を自動生成
- 「PostDTO/CommentDTOの型、FirestoreDataConverter(withConverter)の雛形、validation方針を生成して」
-
集計方針の安全レビュー
- 「いいね数/コメント数/ランキングを、衝突・改ざん・コスト観点でレビューして」
-
AIログ設計レビュー(AI Logic連携)
- 「AIの出力をFirestoreに保存したい。個人情報・トークン・コスト・監査の観点で最小構成を提案して」 (Firebase)
“2026の最新ポイント”として押さえておくメモ🆕
- Firebase Web SDKは v12.8.0(2026-01-14) までリリースノート上で確認でき、Node要件なども更新され続けています (Firebase)
- Firestoreのドキュメントサイズは 最大1 MiB(設計で地味に効く) (Firebase)
- Firebase AI Logicはモデル更新が速く、例えば Gemini 2.0 Flash系のretire日(2026-03-31) のように“期限付き情報”が出ます(設計でモデル名/バージョン保存が役立つ) (Firebase)
- Admin SDKの前提として、Pythonは 3.10+推奨(3.9はdeprecated)、.NETは .NET 8+推奨(6/7はdeprecated) の情報が公式に明記されています (Firebase)