第10章:集計の全体像(いつ計算する?いつ保存する?)🧮✨
この章のテーマはめちゃシンプル👇 「数は、毎回その場で数える? それとも、あらかじめ保存しておく?」 この判断ができるようになると、Firestore設計が一気にプロっぽくなります😎🔥
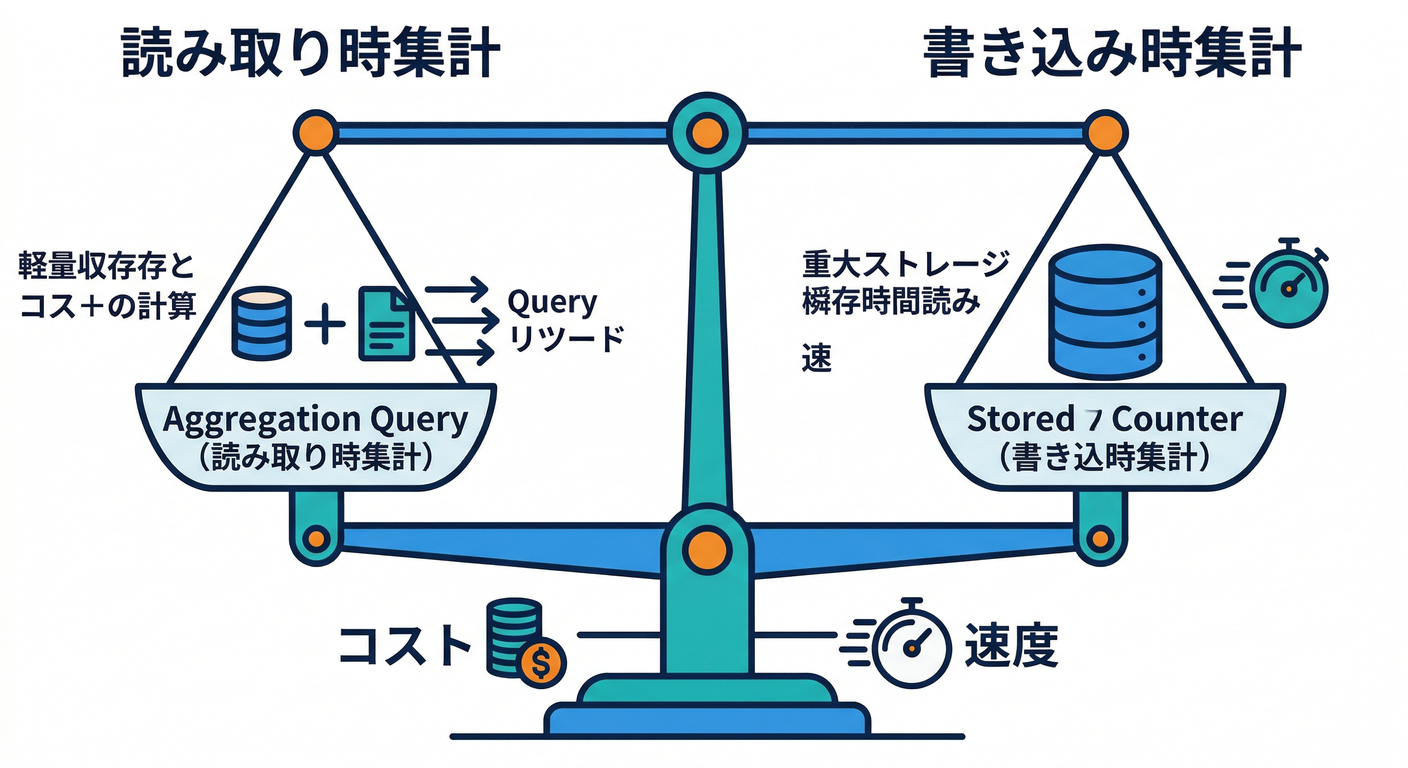
1) まず結論:集計は“2択”+ちょいハイブリッド 🤝
集計は基本この2つです👇
A. その場で数える(Aggregation Queries)📊
- 例:コメント一覧の件数を count() で出す
- 例:コイン合計を sum()、平均を average() で出す
- 結果だけ返ってくるので、全部のドキュメントを読まなくてOK(転送量も減る)👍
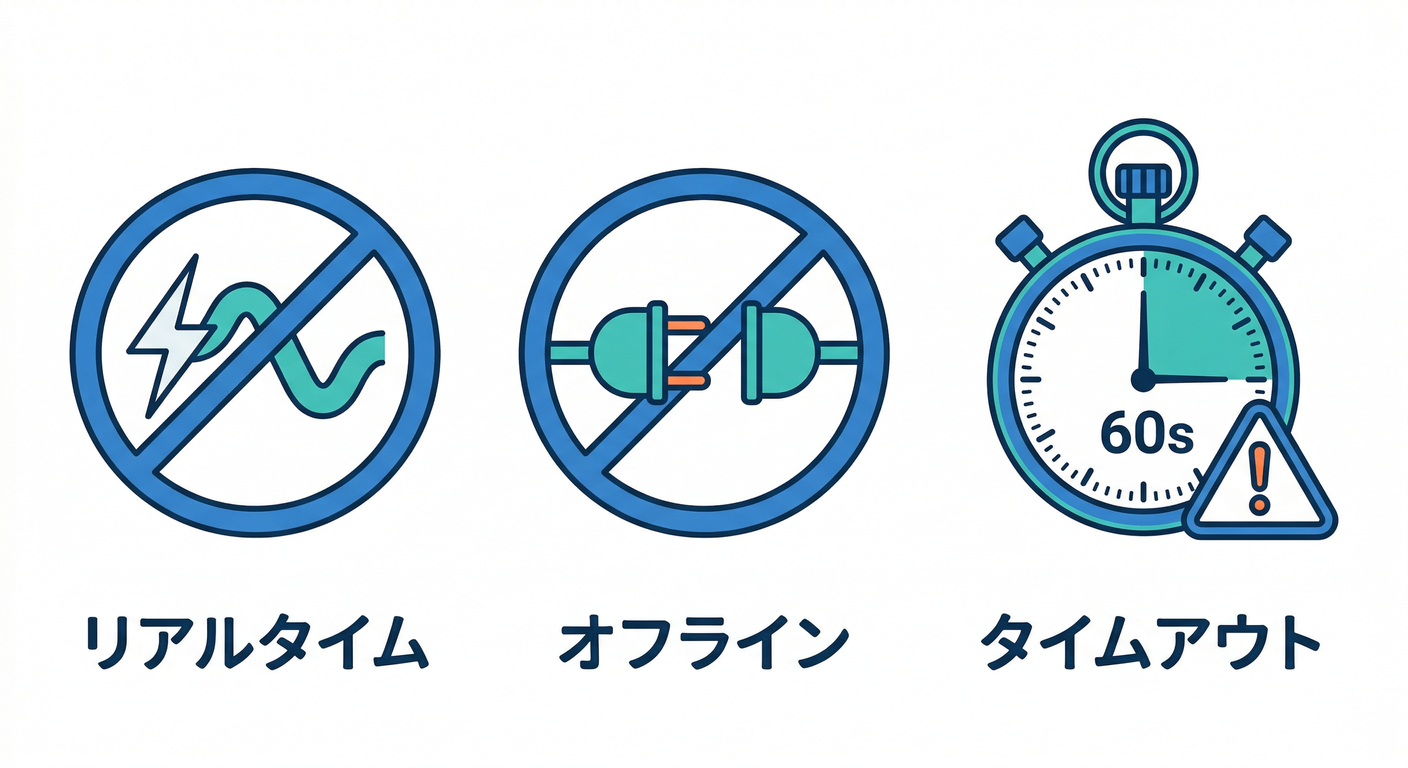
- ただし リアルタイム購読(onSnapshot)では使えない / オフラインキャッシュでも使えない / 大きすぎると60秒でタイムアウト など制約あり⚠️ (Firebase)
B. 保存しておく(カウンタ/ランキング用ドキュメントを持つ)🧱
- 例:
posts/{postId}にcommentsCountを持っておく - 一覧で “各行の件数” を出すとき、毎回count()するとN回問い合わせになりがち😇 → そういう時は保存方式が強い💪
C. ハイブリッド(普段は保存、検証や補助はその場)🔁
- 例:普段の表示は
commentsCount - たまに管理画面だけ「本当に合ってる?」を count() で検算
- 運用で事故りにくいのでおすすめ🥰
2) 今回の題材(日報/記事/コメント)で“集計”を分類しよう 🗂️
この教材の題材でありがちな集計はだいたいこれ👇
- コメント数(
posts/{postId}/commentsの件数) - いいね数(高頻度で増えることがある)
- ランキング(Top N を気持ちよく出したい)
- (AI連携)AI生成回数・AIコスト目安・監査ログ件数 など🤖
ここで大事なのは、集計の“目的”が違うってことです👇
| 集計 | 目的 | ざっくりおすすめ |
|---|---|---|
| コメント数 | UI表示(一覧/詳細) | 一覧→保存 / 詳細→その場 or 保存 |
| いいね数 | UI表示 + 高頻度更新 | 保存(頻度高いなら分散カウンタ寄り) |
| ランキング | Top N を速く | 別コレクションで保存(集計結果を持つ) |
| AIログ件数/利用回数 | 監査/分析 | 保存(ログ)+必要ならその場集計 |
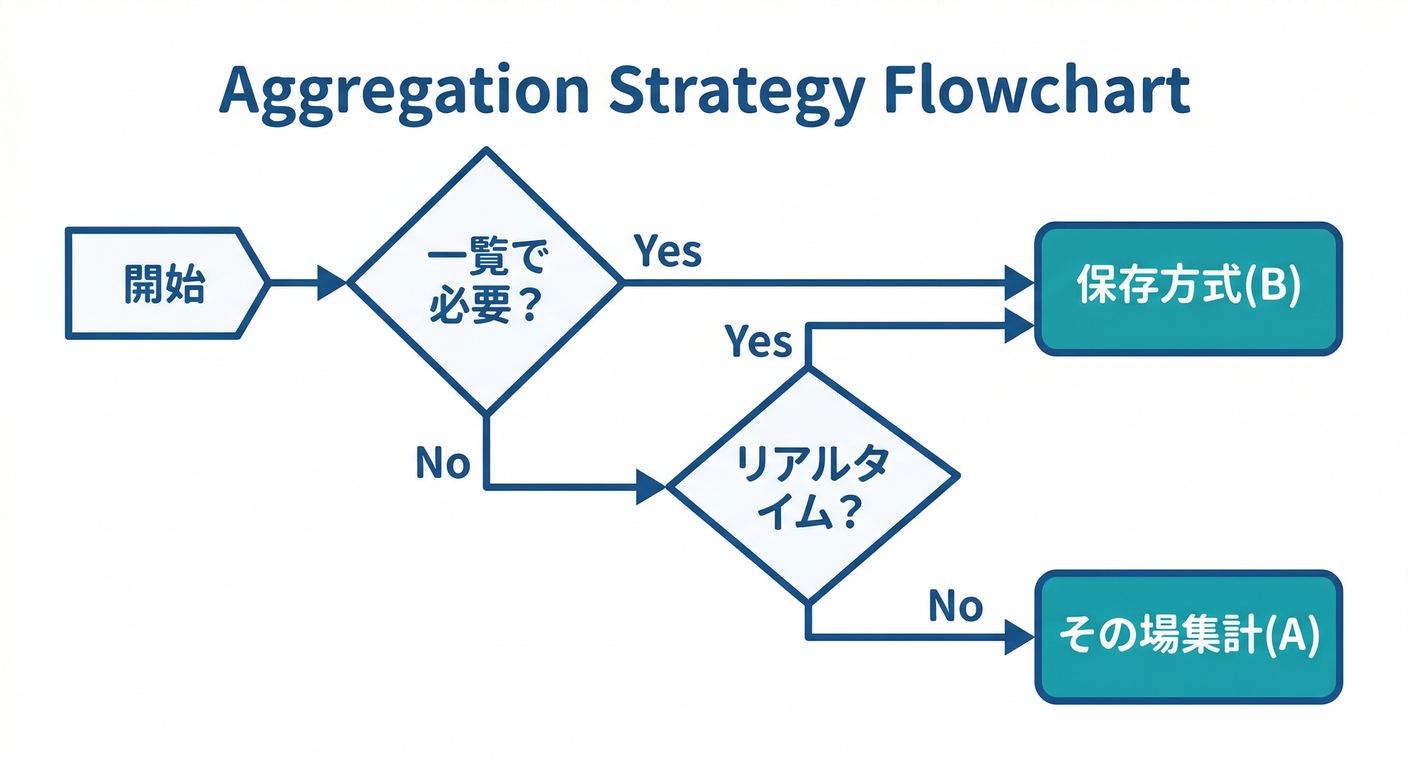
3) 判断フロー(これだけ覚えれば勝ち)✅🧠
次の質問に Yes/No で答えるだけで、だいたい決まります👇
Q1. 一覧で“たくさん並べる”たびに必要? 📜
- Yes → 保存しておくが有利(N回countは地味にキツい)😇
- No(詳細1件だけ) → その場集計でもいけることが多い👍
Q2. リアルタイムで増減が見えないと困る? ⚡
- Yes → 保存方式(+リアルタイム購読)を検討
- No → その場集計でもOK(必要なときだけ叩く)
※集計クエリは リアルタイムリスナー不可&オフライン不可 なので、「常に最新を購読したい」用途と相性が悪いです⚠️ (Firebase)
Q3. 書き込みが集中する(バズる)可能性ある? 🔥
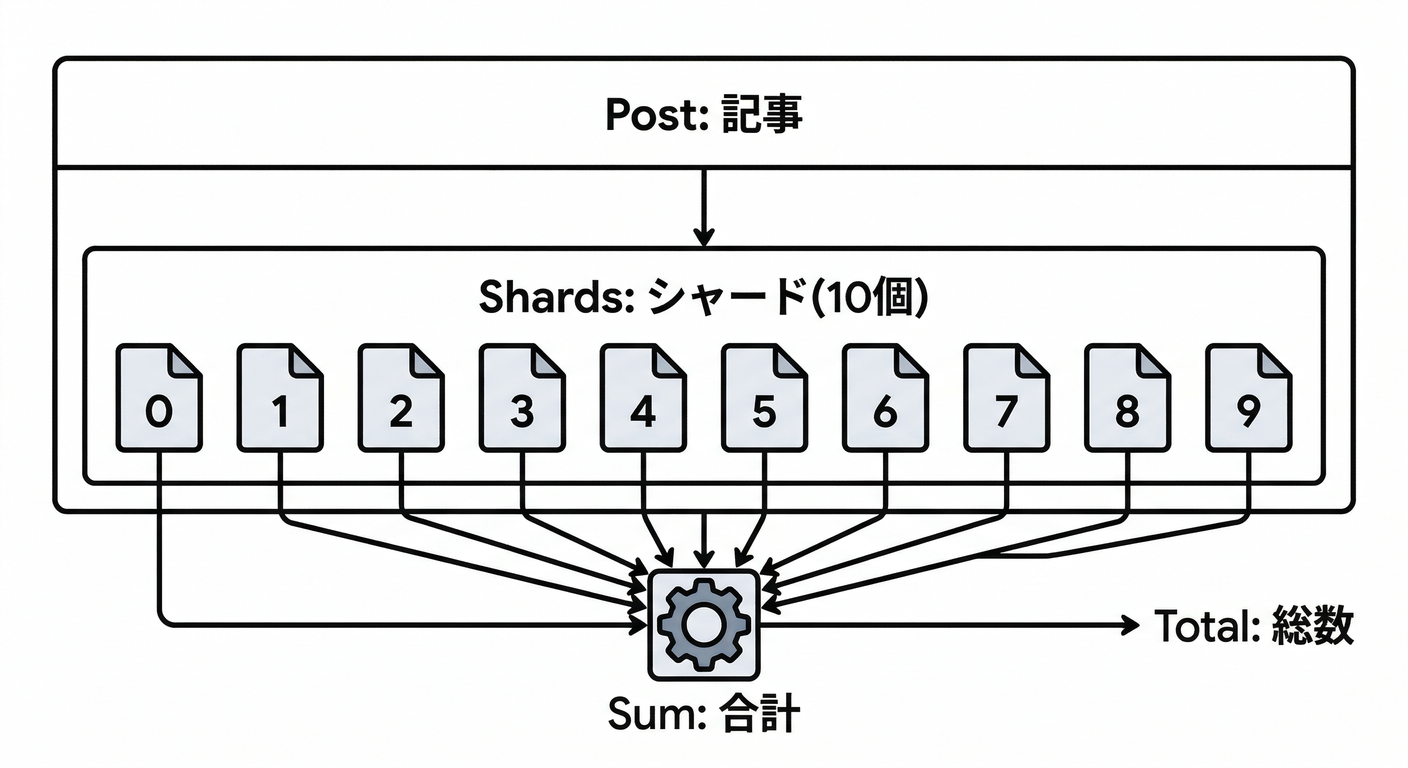
- Yes → “1つのドキュメントに更新集中”を避ける設計へ → 分散カウンタ(シャーディング)などを検討🧱 (Firebase)
- No → シンプル保存(
commentsCount)で十分なことも多い👌
4) 読む:Aggregation Queries(その場集計)の性格を知る📘
4-1. 何ができる?(2026-02時点)🆕
Firestoreの集計クエリは count / sum / average をサポートしています。(Firebase)
Web(TypeScript)だと getCountFromServer() と getAggregateFromServer() が中心です。(Firebase)
4-2. 重要な制約(ハマりどころ)⚠️
- リアルタイム購読(onSnapshot)不可
- オフラインキャッシュ不可(ローカルキャッシュをスキップしてサーバーだけ)
- 60秒で終わらないと DEADLINE_EXCEEDED(データが大きいと起こる)
- 複数集計をまとめられるけど、別フィールドの集計を混ぜると「両方のフィールドを持つドキュメントだけ」が対象になる(結果がズレることがある)
- sum/average は非数値を無視、でも count は非数値も数える(混ぜると“感覚”がズレやすい)(Firebase)
5) 手を動かす:まずは「詳細画面でコメント数」をその場で数える 🧪💬
目的:**「1件の投稿詳細」**で、コメント数だけ欲しいケースを作る(まずはここからが安全)✨
例:posts/{postId}/comments の件数を取得(TypeScript)
import { collection, getCountFromServer } from "firebase/firestore";
import { db } from "./firebase"; // 既に作ってある想定
export async function fetchCommentsCount(postId: string) {
// posts/{postId}/comments
const commentsCol = collection(db, "posts", postId, "comments");
const snap = await getCountFromServer(commentsCol);
return snap.data().count; // number
}
getCountFromServer() は公式例にもある「その場で件数だけ取る」王道です💡 (Firebase)
6) 手を動かす:count + sum + average をまとめて取る(応用)📦✨
目的:複数の集計を1回で済ませる(管理画面や分析っぽい画面で便利)
import { collection, getAggregateFromServer, count, sum, average } from "firebase/firestore";
import { db } from "./firebase";
export async function fetchPostMetrics() {
const postsCol = collection(db, "posts");
const snap = await getAggregateFromServer(postsCol, {
postsCount: count(),
totalLikes: sum("likesCount"),
avgLikes: average("likesCount"),
});
return snap.data();
// { postsCount: number, totalLikes: number, avgLikes: number }
}
getAggregateFromServer() で複数集計をまとめる例は公式に載っています。(Firebase)
⚠️注意:この例だと likesCount が無い投稿が混ざると、集計の対象が期待とズレることがあります(複数集計の仕様)。(Firebase)
7) 保存方式が必要になる“典型パターン”を知ろう 😇📌
パターン1:投稿一覧に「コメント数」を出したい 📜💬
投稿が20件出る画面で、各投稿に count() を打つと 20回問い合わせになりがち💥
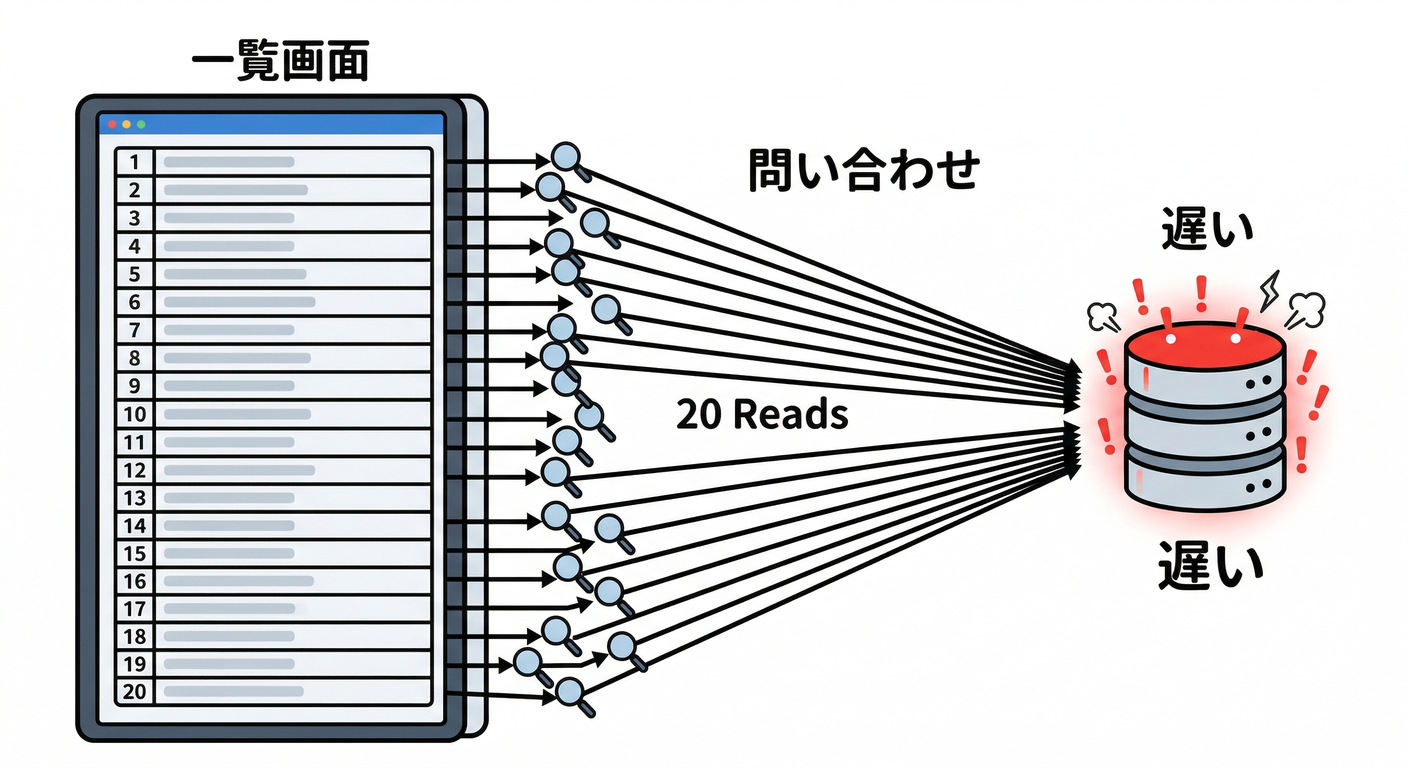 → こういうのはだいたい
→ こういうのはだいたい posts/{postId}.commentsCount を保存が勝ちです🏆
パターン2:いいね数が“バズって”更新集中する ❤️🔥
1つのドキュメントの likesCount に更新が集中すると詰まりやすいので、
必要なら **分散カウンタ(シャーディング)**を検討します🧱
分散カウンタは「shards をサブコレに持って合計で数を作る」公式パターンです。シャード数に比例して書き込み性能が伸びます。(Firebase)
8) AIで設計レビューを爆速にする🤖⚡(Antigravity / Gemini CLI)
8-1. どう使う?(役割分担イメージ)
- Antigravity:複数エージェントで「設計→実装→検証」を回しやすい“ミッション管制”タイプ🚀 (Google Codelabs)
- Gemini CLI:ターミナル上のAIエージェント。検索で根拠を取りながら作業もできるタイプ🔎 (Google Cloud)
8-2. コピペで使える依頼例(第10章用)📎✨
-
集計の方針を3案で比較してもらう
- 「コメント数/いいね数/ランキングをFirestoreで設計。
その場集計と保存とハイブリッドを、コスト/遅延/実装難度/事故りにくさで比較して」
- 「コメント数/いいね数/ランキングをFirestoreで設計。
-
“一覧でN回countしてない?”レビュー
- 「このUI(投稿一覧/投稿詳細)に対して、Firestoreの読み取りが最小になるクエリ設計にして。危ないN+1パターンがあれば指摘して」
-
AIログ(監査)の最小フィールド設計
- Firebase AI LogicはクライアントSDKでAIを安全に呼べて、App Check やレート制限も絡められます。(Firebase)
- 「AI出力をFirestoreに保存する。個人情報を避けつつ、監査・コスト管理・再現性のために必要な最小フィールドを提案して」
9) ミニ課題 🎯📝(10〜15分)
次を A/B/C で分類してみてください👇
 A=その場集計 / B=保存 / C=ハイブリッド
A=その場集計 / B=保存 / C=ハイブリッド
- 投稿詳細画面の「この投稿のコメント数」
- 投稿一覧の「各投稿のコメント数」
- いいね数(将来バズる可能性あり)
- 週間ランキングTop10
- AI生成の「今日の生成回数」(管理画面)
答えの例(目安) 1:A or C、2:B、3:B(必要なら分散寄り)、4:B、5:C(ログは保存+表示だけ集計)✨
10) チェック✅(できたら次章へGO)
- 「その場で数える/保存する」の違いを説明できる🙂
- 集計クエリが リアルタイム不可・オフライン不可・60秒制限 なのを知っている⚠️ (Firebase)
- 一覧で N回count しそうになったら「保存だな」と気づける😇
- いいね等の高頻度更新で 分散カウンタの発想が出る🧱 (Firebase)
次の第11章では、ここで触れた Aggregation Queries(count/sum/avg) を「UIのどこで使うと気持ちいいか」まで落とし込んで、実装の型を作ります📊✨