第12章:イベント処理の設計(冪等・重複・再試行)🧠
今回は「Firestoreイベントで動くFunctions」が、たまに2回動いても壊れないようにする回だよ〜🙂✨ これができると、通知・集計・AI処理が一気に“実務の強さ”になる💪🔥
この章でできるようになること🎯
-
「えっ、同じ通知が2回飛んだ…😱」を設計で防げる
-
失敗したときの**再試行(retry)**を理解して、安全に使える
-
AI(要約/整形)みたいなお金がかかる処理も、重複で爆死しないようにできる💸🧯
-
“壊れない3点セット”を言葉で説明できる
- 冪等(idempotent)
- 重複排除(dedupe)
- 再試行(retry)
1) まず大前提:「イベント駆動」は “1回だけ” を期待しちゃダメ🙅♂️💥
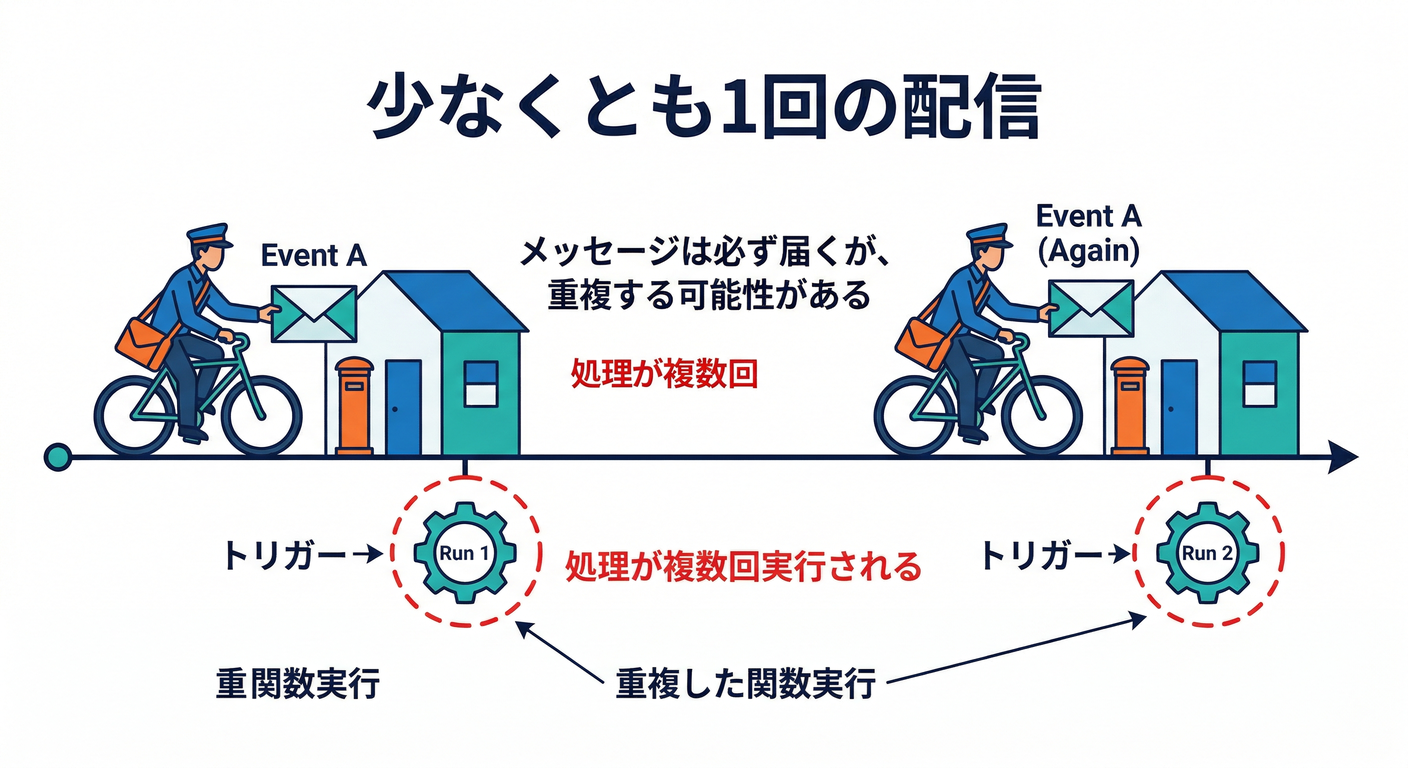
Cloud Functions(イベント駆動)は、仕組みとして at-least-once(最低1回は動く) を提供するよ。つまり、同じイベントが複数回処理される可能性があるってこと。(Firebase)
さらに2nd genは Cloud Run + Eventarc の上に乗ってるので、イベント配信・再試行の世界観もそっち寄りになるよ〜📦🚀(Firebase)
2) 超重要ワード:冪等(idempotent)ってなに?🧩
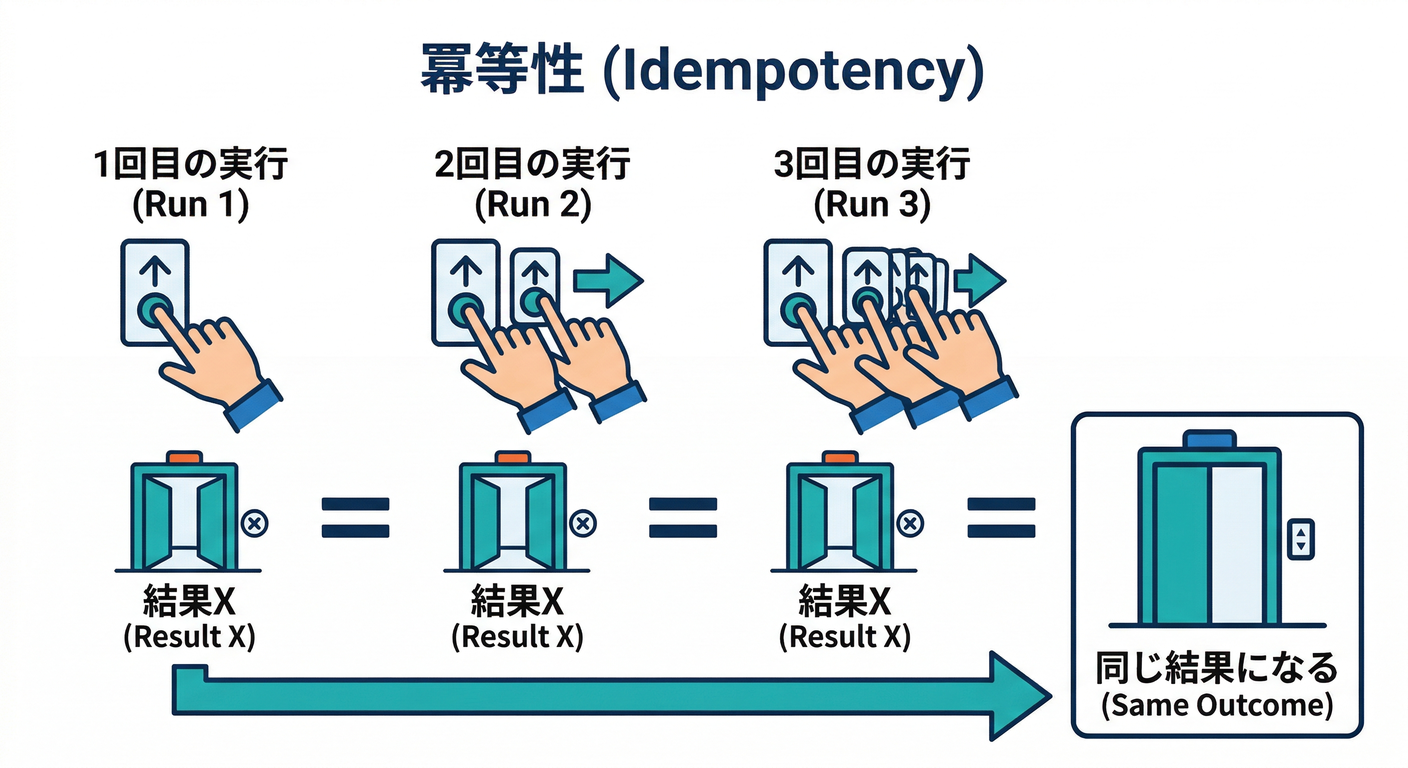
冪等=「同じ処理を2回やっても、結果が変わらない」こと🙂✨
Firebase公式のベストプラクティスでも「冪等に書こう」ってはっきり言ってるよ。(Firebase)
たとえば👇
- ✅ 冪等:
summaryフィールドが既にあれば AI要約をもう作らない - ❌ 非冪等:
likes += 1を毎回やる(2回動いたら+2になる😇)
3) retry(再試行)を正しく怖がる😈➡️😌
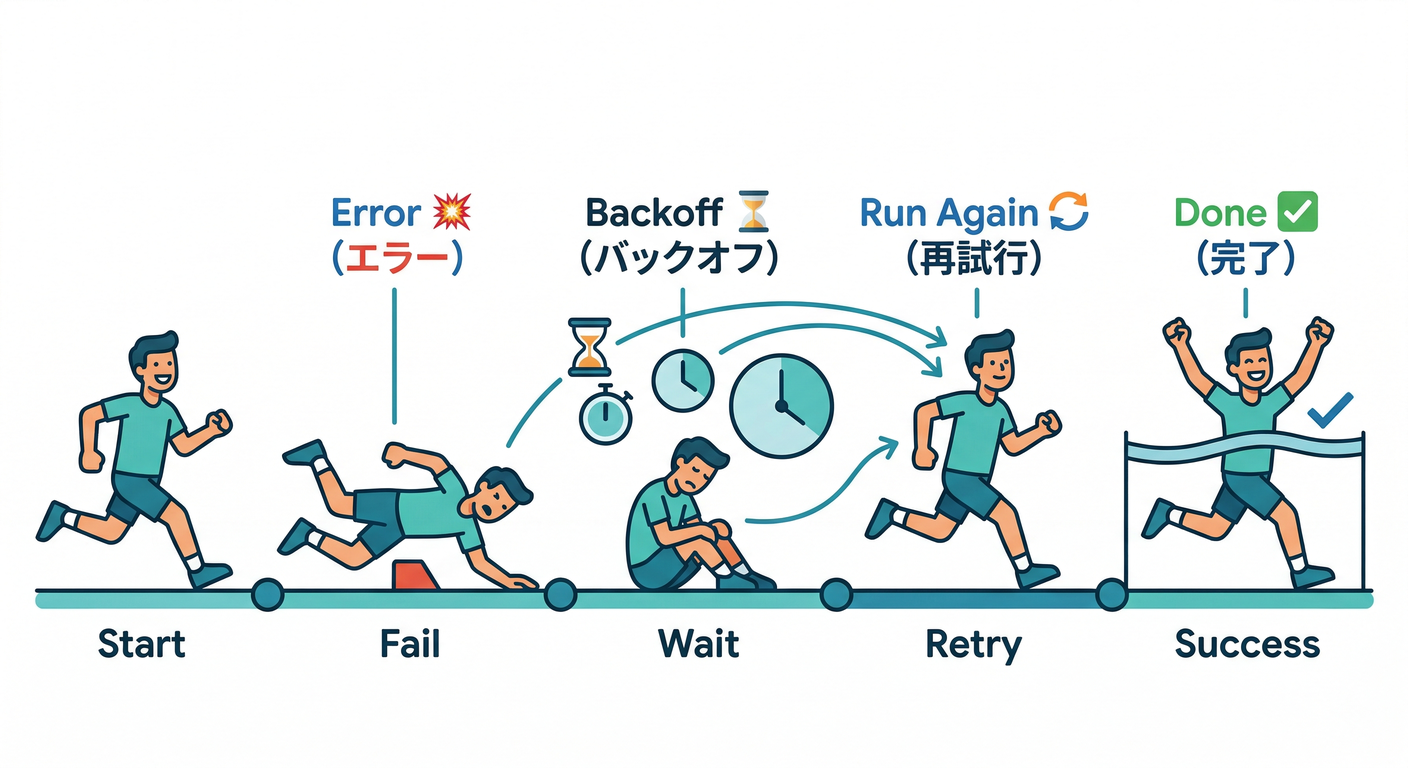
retryの意味🔁
イベント駆動関数は、エラーで終わると **イベントが捨てられる(drop)**ことがある。 そこで retry を有効にすると、成功するか、リトライ期間が切れるまで再実行されるよ。(Firebase)
ただし注意⚠️(無限リトライ地獄)
retry は「バグ」みたいな永久に治らない失敗だと、延々と回って事故る😱 公式も「圧力テストしてから」「一時的な障害向け」と警告してるよ。(Firebase)
4) 壊れないイベント処理の “3本柱” 🏗️✨
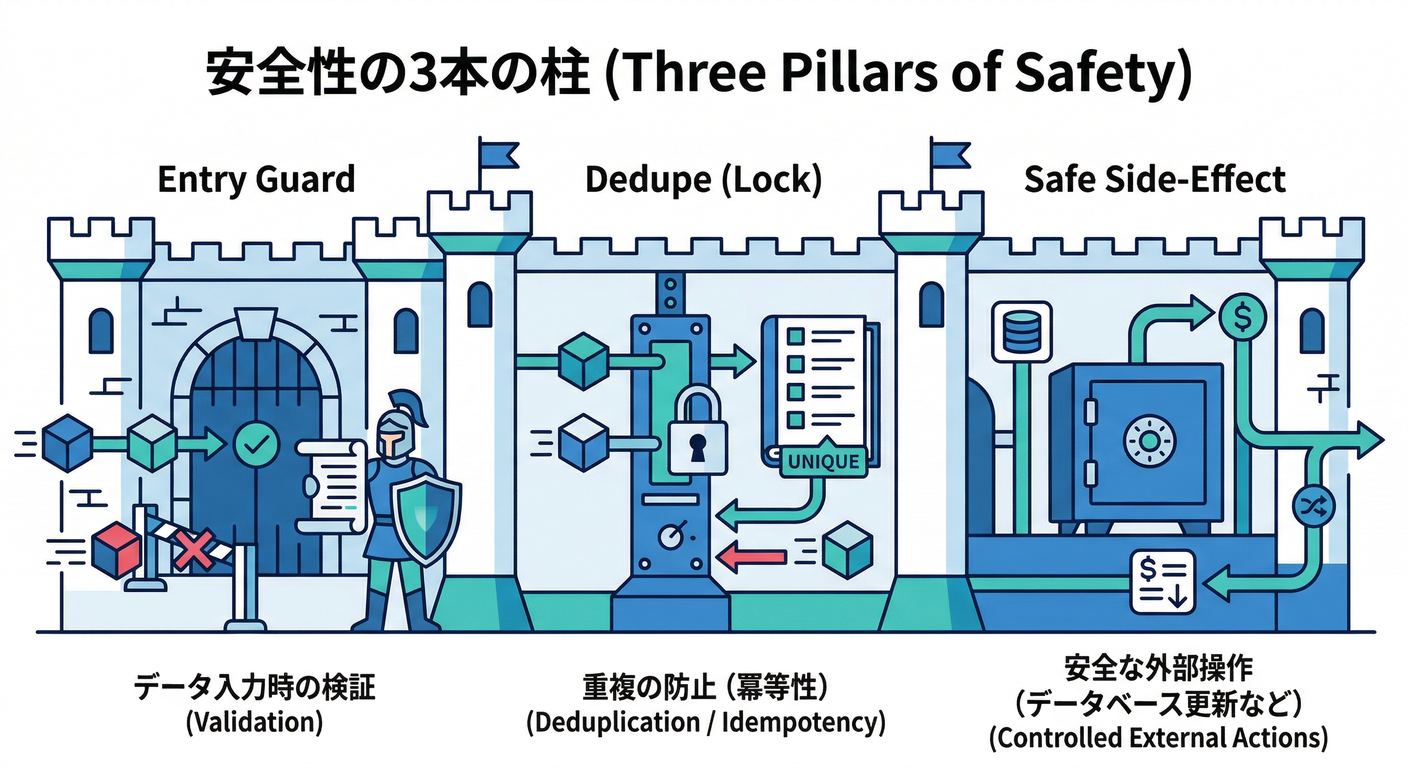
① 入口ガード(早期return)🚪
「このイベントは処理対象?」を最初に判定して、違ったら即return🙂
- 古すぎるイベントは捨てる(retryで遅れて来たやつ対策)
- 必要な変更が無いなら捨てる(自分の書き込みで再発火…の対策)
retryのベストプラクティスでも「終了条件(end condition)を入れろ」って書かれてるよ。(Firebase)
② “処理済み” をどこかに刻む🪵(重複排除)
重複排除の考え方は大きく3つあるよ👇
- A. 元ドキュメントにフラグを書く(わかりやすい)
- B. event.id をキーに “ロック用ドキュメント” を作る(強い)
- C. outbox(ジョブキュー用コレクション)を作る(いちばん実務っぽい)
この章では B を中心にやるよ💪
③ 副作用(Slack通知/外部API/AI呼び出し)を安全にする🧯
副作用は 「1回だけ」 が必要なことが多い。 だから副作用の前に dedupeが必須だよ🙂
あと、Nodeのイベント関数は「終わった後に裏で通信」みたいなのをすると壊れるので、await でちゃんと待って終わらせるの大事⚠️(Firebase)
5) ハンズオン:event.id で二重通知を防ぐ(2nd gen)🛠️🔐
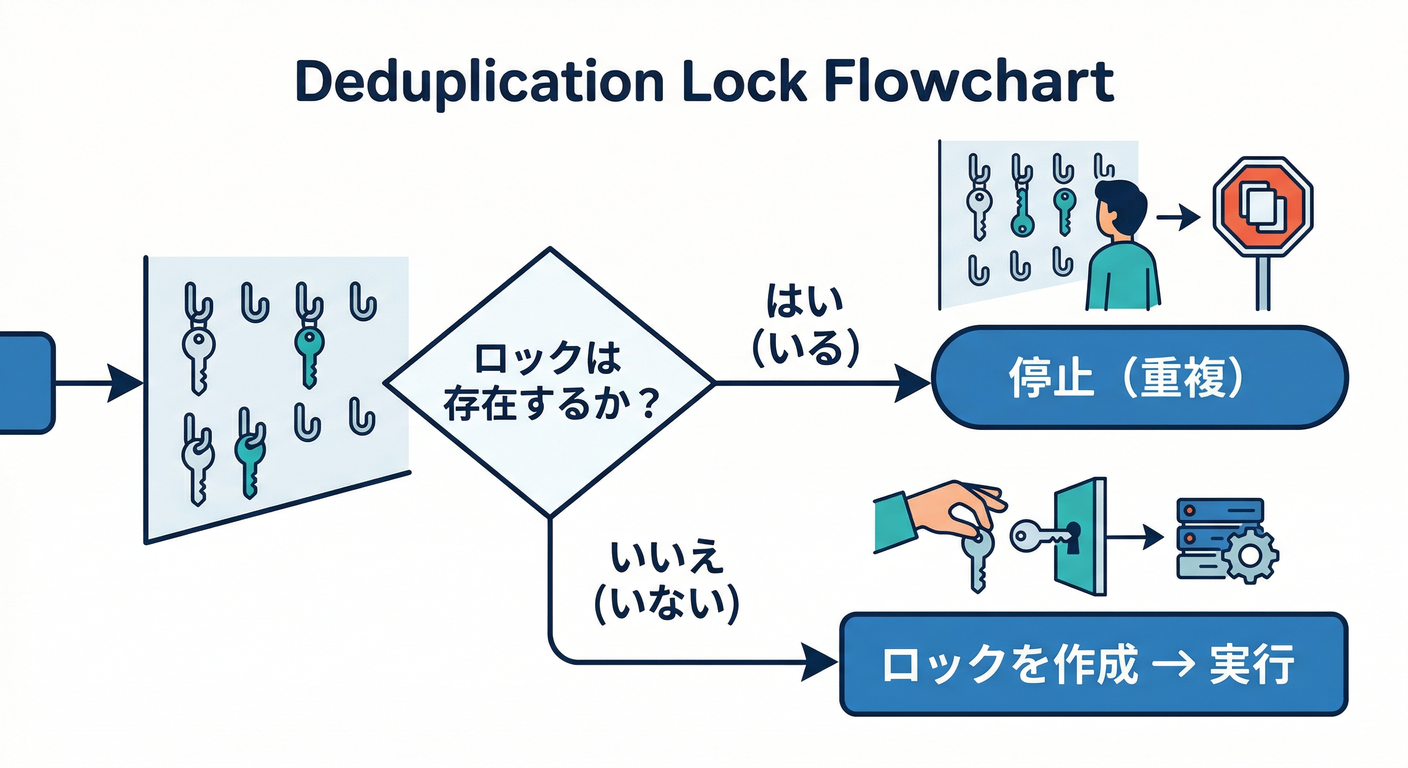
ここから「Slack通知」「AI要約」みたいな 高コスト/高副作用にも効く鉄板パターン!
✅ ポイント:event.id は “このイベント固有のID” として使える🆔
Firebase Functions(2nd gen)のイベントは CloudEvent 形式で、event.id と event.time が取れるよ。(Firebase)
※API参照に “preview” 表記があるので、プロダクションでは念のため「取れない/形式が違う」を想定したフォールバックも用意すると安心🙂(Firebase)
手順①:retry を有効にできる形を知る🔁
2nd gen では、Firestoreトリガー定義のオプションに retry: true を付けられる。(Firebase)
手順②:ロック(dedupe用)コレクションを1個決める🗂️
例:eventLocks/{eventId}
- ここに「このイベントは処理したよ」を刻む
create()(存在したら失敗)を使うと強い💪
手順③:コード例(超重要)🧪
import { onDocumentWritten } from "firebase-functions/v2/firestore";
import { initializeApp } from "firebase-admin/app";
import { getFirestore, FieldValue, Timestamp } from "firebase-admin/firestore";
initializeApp();
const db = getFirestore();
/**
* messages/{id} の更新で動く例
* - 重複排除:event.id をロックに使う
* - 終了条件:古いイベントは捨てる(retry遅延対策)
*/
export const onMessageWritten = onDocumentWritten(
{
retry: true, // 失敗時に再試行(2nd gen)🔁
},
"messages/{id}",
async (event) => {
const eventId = event.id ?? null; // CloudEventのid 🆔
const eventTime = event.time ?? null; // CloudEventのtime ⏱️
// 0) 入口ガード:eventIdが無いなら安全側でやめる(必要ならフォールバック設計)
if (!eventId) return;
// 1) 入口ガード:古すぎるイベントは捨てる(例:10分より前)
if (eventTime) {
const t = new Date(eventTime).getTime();
const now = Date.now();
if (now - t > 10 * 60 * 1000) return;
}
const lockRef = db.collection("eventLocks").doc(eventId);
// 2) “ロック作成” で重複排除(存在したら二重処理しない)
try {
await lockRef.create({
createdAt: FieldValue.serverTimestamp(),
state: "processing",
});
} catch (e: any) {
// 既にロックがある=過去に処理開始済み(重複イベント)✅
return;
}
try {
// 3) ここから本処理(例:AI要約を作って保存、Slack通知など)
// ※AIや外部APIは “重複するとコスト爆増” なので、ここに来るまでにdedupe必須💸🧯
// ... 例:Firestore更新、AI生成、Slack送信(awaitで必ず待つ)
// 4) 成功したらロックをdoneへ
await lockRef.update({
state: "done",
doneAt: FieldValue.serverTimestamp(),
});
} catch (err) {
// 5) 失敗したら state=error にして原因を刻む(観測しやすい)
await lockRef.update({
state: "error",
errorAt: FieldValue.serverTimestamp(),
});
// retry を効かせたいなら “throw” で失敗扱いにする
throw err;
}
}
);
このコードの狙い🎯
- 同じイベントが2回届いても、2回目は
create()が失敗して即return → 二重通知を防ぐ✅ - 失敗時に
throwすると retry の対象になる(設定している場合)(Firebase) - retry は最大24時間なので「古いイベントは捨てる」終了条件が効く(Firebase)
でも!落とし穴もある😱(ここ超大事)
上の実装だと👇こうなる可能性がある:
- ロック作成 ✅
- Slack送信で失敗 ❌
- retryで再実行 🔁
- でもロックがあるから return 😇(=Slackが結局送れない)
だから実務では、ロックに 状態 を持たせて「done以外なら再試行OK」にすることが多いよ🙂✨
(例:state: processing が一定時間以上続いてたら “やり直しOK” にする、など)
6) AIを絡めるときの“重複対策”は最優先🧠💸🤖
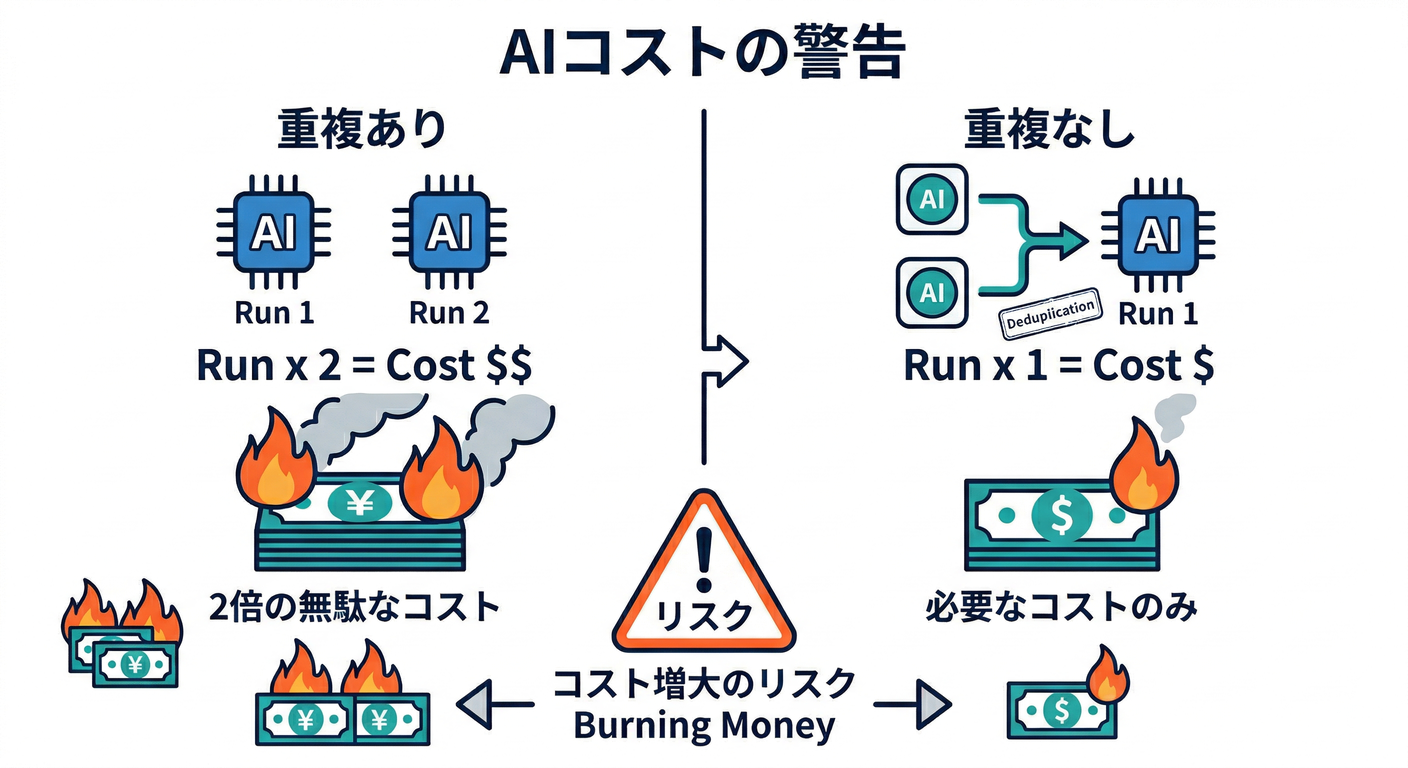
AIをイベント処理に入れると、重複実行で 費用も遅延も倍増しがち😇 だから「AIを呼ぶ前にdedupe」or「AI結果を保存して再利用」が必須!
例:AI要約を一度だけ作って保存📌
- 先に
summaryがあるか確認 - 無ければ生成して保存
- 生成後の保存も「同じ結果に収束する」ようにする(冪等)
Firebaseの生成AI系は大きく2系統で考えると整理しやすいよ👇
- アプリ側(クライアント)から呼ぶ:Firebase AI Logic(旧 Vertex AI in Firebase)(Firebase)
- サーバ側(Functions)でAIワークフロー:Genkit +
onCallGenkitなど(Firebase)
7) 開発を速くする:Antigravity / Gemini CLI / MCP 🛸🧰🤖
この章の“設計テンプレ”は、AIにレビューさせると強いよ🙂 たとえば👇
- 「この関数、二重実行で壊れない?」チェックリスト生成
- “失敗→retry→再実行” のテスト観点を列挙
- ロック設計(state遷移)案を複数出す
Gemini CLIにはFirebase拡張があって、Firebase文脈に強い動きをさせやすいよ。(Firebase) さらに MCP server を入れると、AI支援ツールがFirebaseプロジェクトやコードベースを扱いやすくなる。(Firebase)
8) ミニ課題(この章のゴール)🏁✨
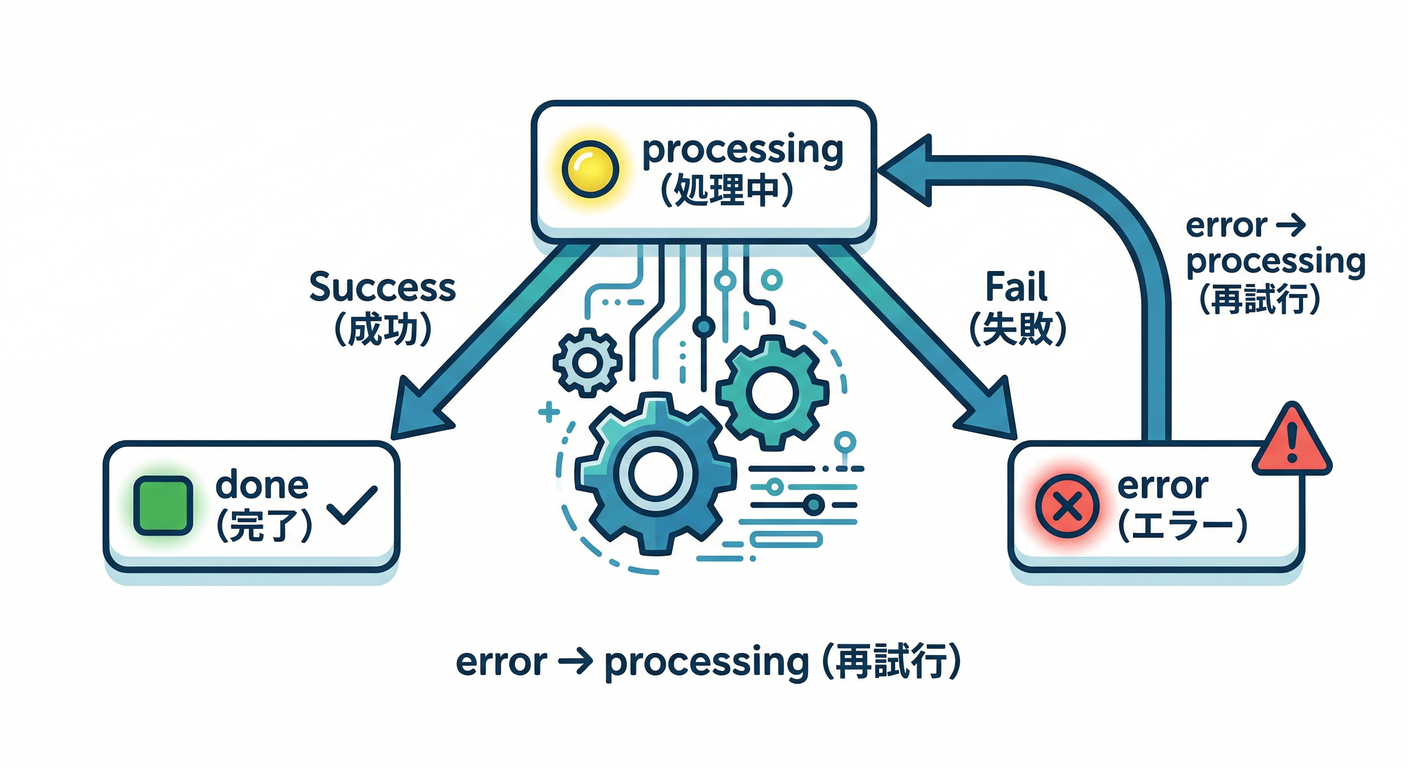
お題:二重通知を防ぐ作戦を完成させる📨🧠
eventLocks/{eventId}を作るcreate()で重複排除- 失敗したら
throwで retry(必要なら) - done / error / processing の状態を入れて、再試行で詰まらないようにする
✅ できたら「二重通知を防ぐ作戦」を自分の言葉で説明してみてね🙂✨
9) チェック(言えたら勝ち)✅🧩
- 冪等って何?(一言で)
- retry をオンにすると何が起こる?(良い点/怖い点)(Firebase)
- event.id を使って二重処理を防ぐ理由は?(Firebase)
- AIを入れるとき、重複対策が特に大事なのはなぜ?(Firebase)
おまけ:別言語でも考え方は同じだよ🧩🐍💠
Firebase Functionsの中心はNode/TSだけど、イベント駆動の世界観(at-least-once / retry / 冪等)は、Pythonでも .NETでも同じ発想で戦えるよ。 Cloud Run functions側のランタイム情報は公式の runtime support を見るのが確実🙂(Google Cloud Documentation)
次の第13章は、ここで作った“壊れない設計”を使って 通知・集計 の王道パターンに突入するよ📣📊🔥