第1章:Firestore設計って何を決めるの?(最短で地図を作る)🗺️✨
この章は「いきなり保存形(スキーマ)を考えない」がコツです😄 まず 画面 → 必要な取り出し方(クエリ) を決めて、そこから逆算して「保存形」を決めます💪
0) この章でできあがるも�
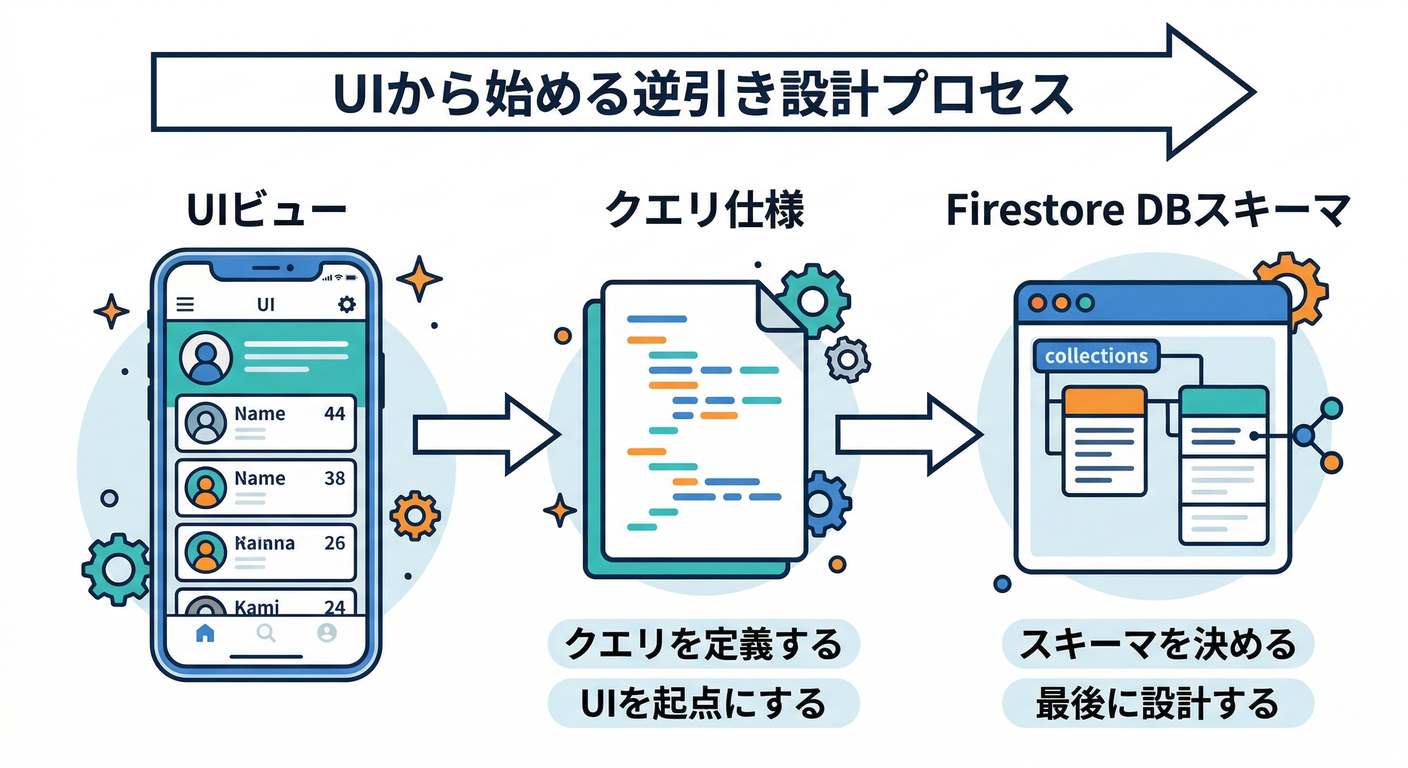
Firestoreは コレクション に ドキュメント を入れる形が基本で、ドキュメントの下に サブコレクション も作れます📚(入れた瞬間に“勝手にできる”感覚が特徴)(Firebase)
で、設計で本当に決めるべきはこれ👇
- どんな画面がある?🖥️📱
- その画面は「どういう条件」で「どういう順」に「何件」ほしい?🔎
- リアルタイム更新いる?⚡
- 次ページ(無限スクロール)いる?📜
さらに大事な現実ポイントもひとつだけ先に知っておくと楽です👇 Firestoreは、クエリの形によって 必要なインデックス が決まります🧭(複合インデックスが必要になるパターンがある)(Firebase) そして課金面でも「読み取りは、クエリを満たすために読まれたドキュメント(+インデックス)に基づく」ので、クエリ設計がコストにも直結します💸(Firebase)
2) 手を動かす:まず「画面」を3枚、雑でいいから描く📝🎨
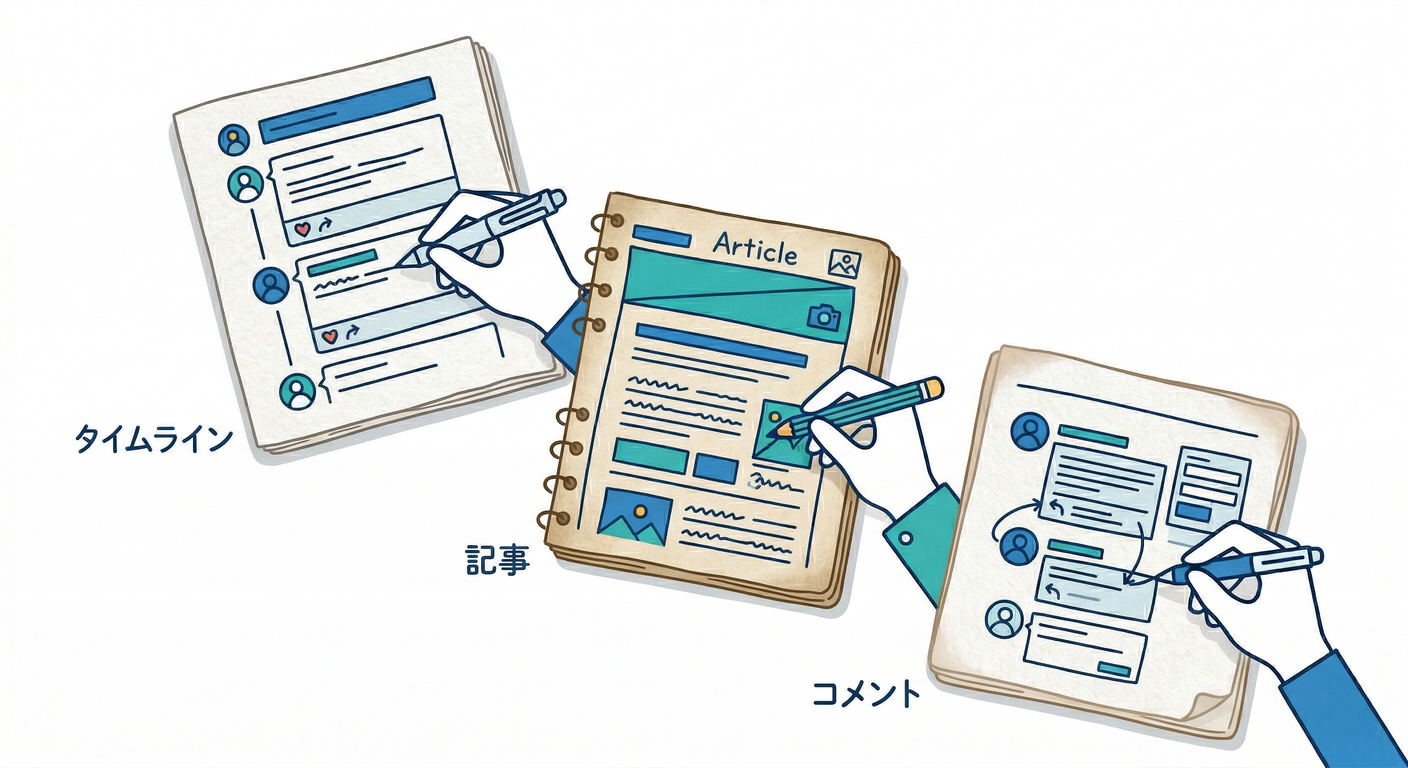
紙でも、付箋でも、Windowsならメモ帳でもOKです🙆♂️ 上手に描く必要ゼロ。大事なのは「何を表示するか」です😄
画面A:記事一覧(タイムライン)📜
最低これだけ書く👇
- 表示:タイトル / 投稿者名 / いいね数 / 最終更新 / コメント数
- 並び:新しい順?人気順?(まずは新しい順でOK)
- 何件:20件
- 次ページ:いる(無限スクロール想定)
- リアルタイム:いる?(最初は “なくてもOK” で判断)
画面B:記事詳細📄
- 表示:本文 / 投稿者 / createdAt / いいねボタン
- 取得:1件読み(docを読むイメージ)
画面C:コメント欄💬
- 表示:コメント本文 / 投稿者 / createdAt
- 並び:古い順?新しい順?(どっちでもいいけど、決めるのが大事)
- 何件:最初50件 → 追加読み
- リアルタイム:いる?(コメントはリアルタイムが気持ちいい⚡)
3) 手を動かす:クエリを最低10本 “文章で” 書き出す🔎🧠
ここでのクエリは「コード」じゃなくてOK! 人間が読める仕様として書きます✍️
書き方テンプレ👇(これを1行ずつ増やすだけ)
- 目的(どの画面?)
- 対象(どのコレクション?どのパス?)
- 条件(絞り込み)
- 順番(並び替え)
- 件数(limit)
- ページング(次ページの基準)
- リアルタイム(要/不要)
例:クエリ10本(コピって自分用に直してOK)🧩
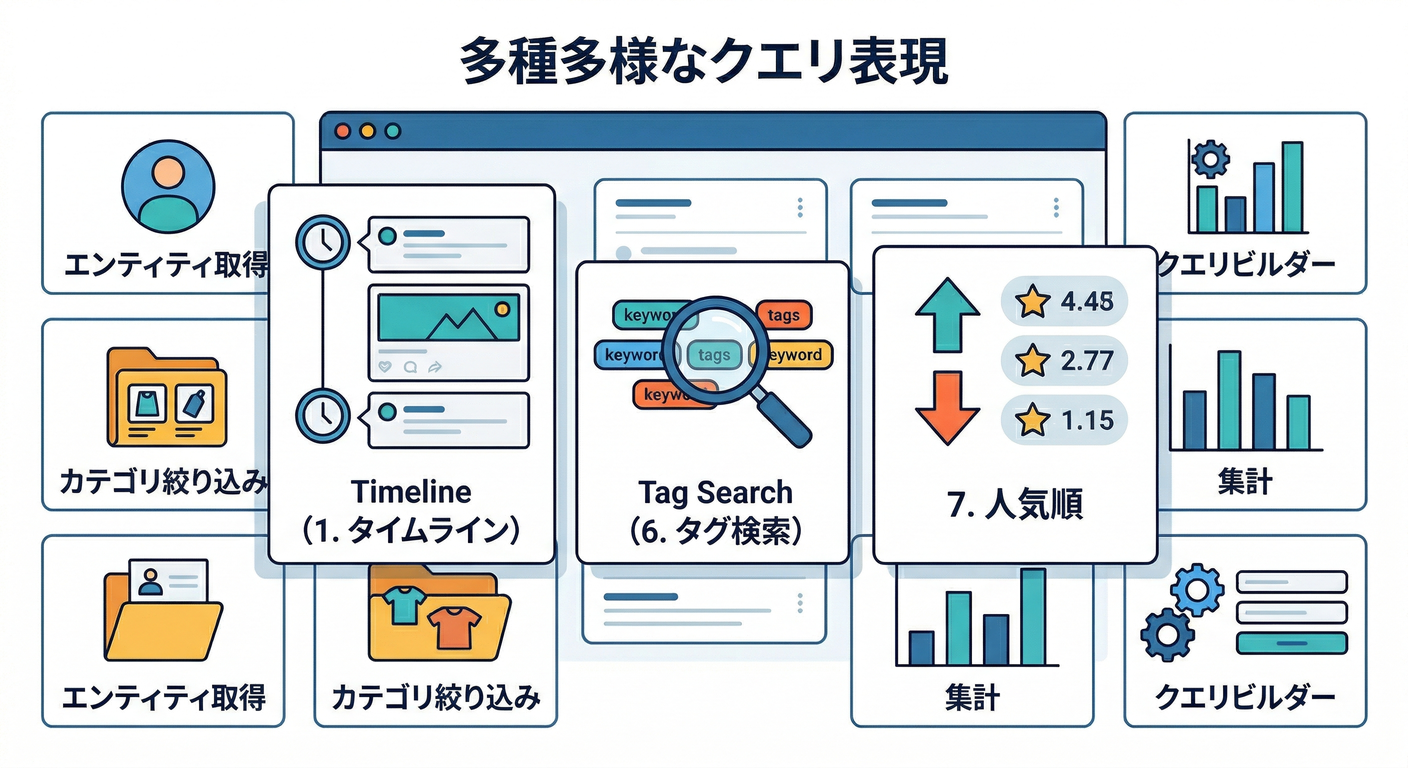
- 記事一覧:記事を 新しい順 に20件
- 記事一覧:自分の投稿だけを 新しい順 に20件
- 記事詳細:指定IDの「記事を1件」読む
- コメント欄:指定記事のコメントを 古い順 に50件
- コメント欄:次ページ(最後に読んだコメント以降)を50件
- 記事一覧:タグ「firebase」を含む記事を新しい順に20件
- 記事一覧:人気順(likesCount順)に20件(同点の並びも決める)
- 記事一覧:「最近コメントが付いた順」に20件(※そのためのフィールドが要るかも)
- 管理/自分用:自分の最近コメント(横断的に)を新しい順に20件
- 監査ログ:AI出力を保存したログを新しい順に50件(後でAI運用が超楽になる)🤖
この時点で、必要フィールドが浮かんできます👇(これが“逆算”の感覚!)
- createdAt(並びに必要)
- authorId(自分の投稿に必要)
- tags(タグ検索に必要)
- likesCount(人気順に必要)
- lastCommentAt(最近コメント順に必要かも)
あと、ドキュメントは最大サイズが決まってるので「1つのドキュメントに詰め込みすぎない」が前提として効いてきます📦(Google Cloud Documentation)
4) ミニ課題:クエリ仕様書 v0 を完成させよう🧾✅
クエリ10本それぞれに、最後の2項目を追加して完成です✨
-
このクエリのために必要なフィールドは?(createdAt / authorId など)
-
このクエリのために“複製して持つ”のが楽な情報は?
- 例:一覧で投稿者名を出したい →
authorNameを記事側にも複製する案が出る(後の章で正規化/非正規化を判断する材料になる⚖️)
- 例:一覧で投稿者名を出したい →
5) AIで設計レビューを爆速にする🤖⚡(Antigravity / Gemini CLI / FirebaseのAI)

- 目的(どの画面?)
- 対象(どのコレクション?どのパス?)
- 条件(絞り込み)
- 順番(並び替え)
- 件数(limit)
- ページング(次ページの基準)
- リアルタイム(要/不要)
例:クエリ10本(コピって自分用に直してOK)🧩
- 記事一覧:記事を 新しい順 に20件
- 記事一覧:自分の投稿だけを 新しい順 に20件
- 記事詳細:指定IDの「記事を1件」読む
- コメント欄:指定記事のコメントを 古い順 に50件
- コメント欄:次ページ(最後に読んだコメント以降)を50件
- 記事一覧:タグ「firebase」を含む記事を新しい順に20件
- 記事一覧:人気順(likesCount順)に20件(同点の並びも決める)
- 記事一覧:「最近コメントが付いた順」に20件(※そのためのフィールドが要るかも)
- 管理/自分用:自分の最近コメント(横断的に)を新しい順に20件
- 監査ログ:AI出力を保存したログを新しい順に50件(後でAI運用が超楽になる)🤖
この時点で、必要フィールドが浮かんできます👇(これが“逆算”の感覚!)
- createdAt(並びに必要)
- authorId(自分の投稿に必要)
- tags(タグ検索に必要)
- likesCount(人気順に必要)
- lastCommentAt(最近コメント順に必要かも)
あと、ドキュメントは最大サイズが決まってるので「1つのドキュメントに詰め込みすぎない」が前提として効いてきます📦(Google Cloud Documentation)
4) ミニ課題:クエリ仕様書 v0 を完成させよう🧾✅
クエリ10本それぞれに、最後の2項目を追加して完成です✨
-
このクエリのために必要なフィールドは?(createdAt / authorId など)
-
このクエリのために“複製して持つ”のが楽な情報は?
- 例:一覧で投稿者名を出したい →
authorNameを記事側にも複製する案が出る(後の章で正規化/非正規化を判断する材料になる⚖️)
- 例:一覧で投稿者名を出したい →
5) AIで設計レビューを爆速にする🤖⚡(Antigravity / Gemini CLI / FirebaseのAI)
ここからが2026っぽい進め方です😄 AIには「スキーマを丸投げ」じゃなくて、あなたが作った“クエリ仕様書”をレビューさせるのが最強です💪
使い方のイメージ(超ざっくり)🛰️
- Antigravity:複数エージェントが計画→実行→検証まで進める“ミッションコントロール”型の開発体験、みたいな立ち位置です🚀(Google Codelabs)
- Gemini CLI:ターミナルから使えるAIで、Cloud Shellなら追加セットアップなしで触れる案もあります🧑💻(Google for Developers)
コピペ用プロンプト(まずはこれだけでOK)📎
あなたはFirestore設計レビュアーです。 以下が「画面」と「クエリ仕様書」です。
コメントをサブコレにする案
コメントをトップレベルにする案 を出して、各案ごとに
- 実現できるクエリ / 苦手なクエリ
- 必要になりそうなインデックス
- 更新が大変になりそうな点(likesCountやlastCommentAtなど) を箇条書きで比較してください。 (最後に“おすすめ案”と理由もください)
AIをアプリに入れるときは、レート制限やApp Checkなど「事故りにくい運用」が重要になります🛡️(たとえばFirebase AI Logicのデフォルトは 1ユーザーあたり100 RPM など)(Firebase) このへんは後の章でガッツリやりますが、第1章では「ログ設計を最初からクエリに入れておく」と後でめちゃくちゃ助かる、だけ覚えておけばOKです😄🤖
6) チェック(できたら次へ)✅✨
次の質問に “うん” って言えたら勝ちです🏆
- 画面からクエリを逆算できた?🗺️
- クエリが10本以上ある?🔟
- 各クエリに「並び順」と「件数」が入ってる?📏
- 「このクエリのために必要なフィールド」を言語化できる?🧠
- “最近コメント順”みたいに、欲しい取り出し方のために 専用フィールドが必要かも と気づけた?💡
よくある失敗(先に踏んでおく)😵💫💥

- 「とりあえず保存してから考える」→ 後からクエリが作れず地獄😇
- 並び順を決めない → 一覧もページングも不安定📜💥
- 何でも1ドキュメントに詰める → サイズ制限や運用がつらい📦(Google Cloud Documentation)
- コスト感ゼロで “全部読む” 方向へ → クエリ設計がコストに直撃💸(Firebase)
次章予告➡️ 第2章:エンティティ分解(User / Report / Post / Comment)🧩
第1章で作った「クエリ仕様書 v0」をもとに、次は 登場人物(エンティティ) を分解して、必須フィールドを決めます✍️✨ ここまで来ると、設計が一気に“現実の形”になりますよ😄🔥