第6章:正規化 vs 非正規化(Firestore流の割り切り)⚖️
この章はズバリ、Firestore設計のいちばん悩むところ―― **「同じ情報を複製していいの?ダメなの?😵」**をスッキリさせます✨
Firestoreは 大量の“小さいドキュメント”を高速に扱うのが得意なDBです📦⚡(テーブル結合でガツン!という世界観ではない)(Firebase) なので設計も、**“JOINしない前提で、読みやすい形に寄せる”**のがコツになります😄
1) 読む:まず結論(Firestore流の割り切り)🧠✨
✅ 正規化 / 非正規化って超ざっくり何?
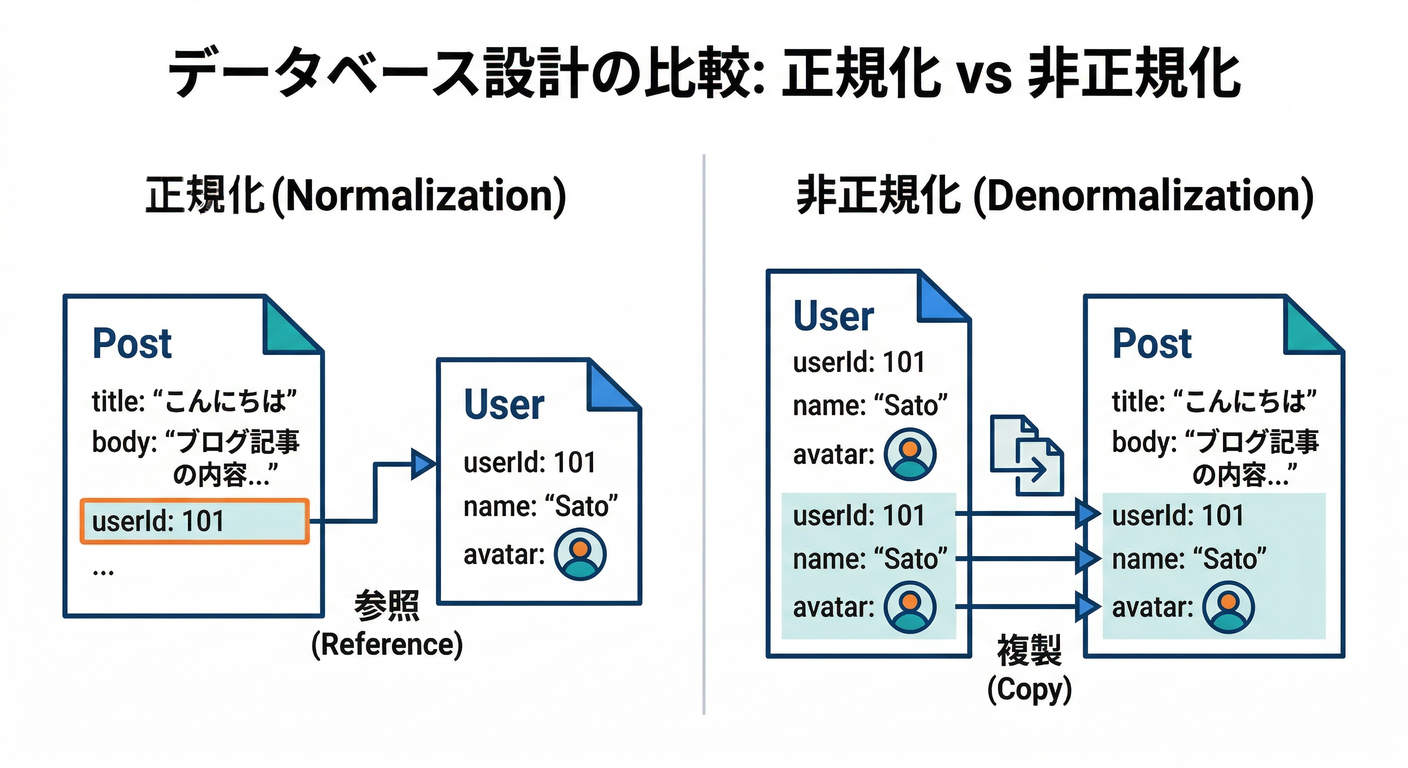
- 正規化:情報は1か所に集約(例:ユーザー名は
users/{uid}にだけ保存)🗄️ - 非正規化:表示のために必要な情報を複製(例:
posts/{postId}にもauthorNameを持つ)🪞
Firestoreだと、画面を作るときに 「投稿一覧に投稿者名もアイコンも出したい!」みたいな要求がめちゃ多いので、**表示用の複製は“アリ寄り”**になります🫶
2) なんでFirestoreは“複製OK”になりがち?🤔
理由は3つあります👇
(A) “小さいドキュメントを大量に”が得意 📄📄📄
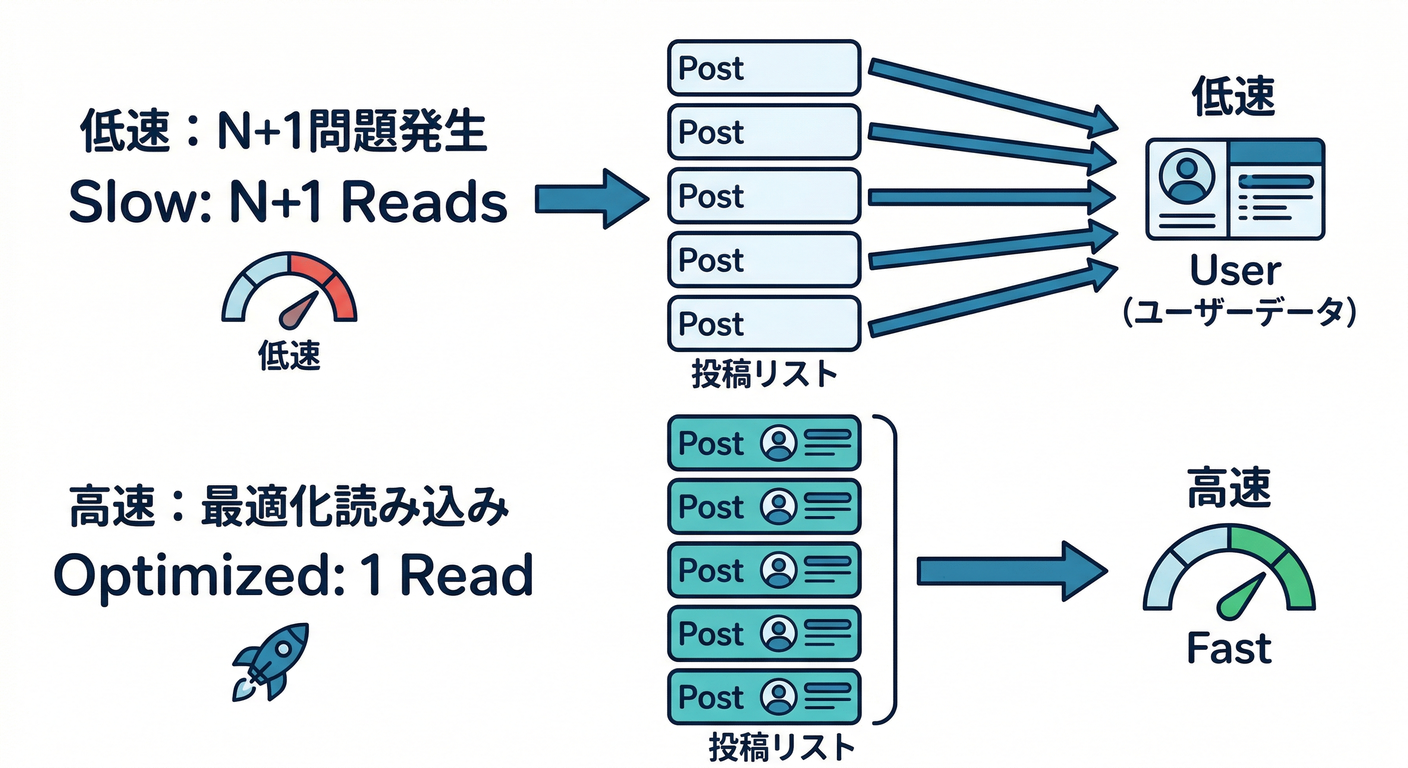
Firestoreは 大きい塊をドン!より、軽量ドキュメントをサクサクが得意です(Firebase) だから 一覧表示のたびに追加で何回も読み込みが起きる設計だと、体験的にもコスト的にも重くなりがち😵💫
(B) ドキュメントサイズは最大 1 MiB 🚧
「複製しすぎて1ドキュメントが太る」事故があるので、そこは注意⚠️ Firestoreのドキュメントサイズ上限(1 MiB)は設計に地味に効きます(Firebase) (※サブコレのドキュメントは親ドキュメントサイズに含まれないのは救い✨)(Firebase)
(C) 書き込みは“インデックス更新”もセットで走る 🧾➡️🧾
Firestoreの書き込みは、ドキュメント本体だけじゃなく関連インデックスの更新も一緒に走ります(Google Cloud Documentation) つまり複製フィールドが増えるほど、書き込み時の更新対象も増えやすいんですね😇
3) 例で理解:投稿一覧の「投稿者名/アイコン」問題 👤📰
「記事一覧」画面で、各記事に
- 投稿者名(displayName)
- 投稿者アイコン(photoURL)
を出したいとします😄
案A:正規化寄り(postsはauthorIdだけ持つ)🗄️
posts/{postId}:authorIdだけ保存- 画面:投稿一覧を取ったあと、各投稿ごとに users/{uid} を読む
👍 良い
- ユーザー名変更がすぐ反映される✨(常にusersが正)
- データの一貫性が高い💎
👎 つらい
- 一覧で投稿が20件あると、追加で20回ユーザー読みに行きがち(工夫はできるけど)😵
- UI実装がやや面倒(キャッシュ/バッチ取得/重複排除など)🌀
案B:非正規化寄り(postsにauthor表示情報も持つ)🪞
posts/{postId}:authorIdに加えてauthorName,authorPhotoURLも保存
👍 良い
- 一覧が軽い!読み取り回数が減ってサクサク⚡
- クエリだけで画面が完結しやすい😄
👎 つらい
-
ユーザー名変更したとき、過去投稿の複製をどうする?問題が発生💥
- “過去は古いままでもOK(スナップショット)”にするのか
- “全部更新して整合性を保つ”のか
4) じゃあどう判断する?迷ったらこの3問🧩
複製するか迷ったら、これだけ考えればOKです👇✨
- それ、一覧で何回読む?(読み回数が多いなら複製は有利)📜
- その値、どれくらい変わる?(変わりやすいなら複製は慎重)🔁
- 古い表示が残っても許せる?(OKなら“スナップショット複製”が強い)🕰️
5) 手を動かす:日報/記事/コメントの「複製ライン」を決めよう ✍️🔥
ここから実作業です! 「記事に表示したい投稿者情報」を **“どこまで複製する?”**を決めます😄
Step 1:まず型で“置き場所”を可視化する 🧱
// 公開用ユーザー情報(表示に使う最小セット)
export type UserPublic = {
uid: string;
displayName: string;
photoURL: string | null;
// 追加したくなりがち:handle, bio など
};
// 記事(posts)の保存形
export type PostDoc = {
title: string;
body: string;
createdAt: unknown; // Timestamp想定(ここではunknownでOK)
authorId: string;
// ✅ 非正規化:表示用スナップショット
authorDisplayName: string;
authorPhotoURL: string | null;
};
ポイントはこれ👇 **“authorId(参照) + 表示用スナップショット”**のセットがめちゃ使いやすいです🎯
Step 2:複製していいフィールドの“鉄板”を知る 🥇
複製OKになりやすい(表示専用)
displayName(表示名)🙂photoURL(アイコン)🖼️handle(@name)🐦roleLabel(一般/管理者など ただし権限判断には使わない!)🔐
複製しない方がいい(意味が強い/変更されやすい/危険)
- 権限の根拠(admin判定とか)🚫
- 課金状態/プラン状態💳
- メールアドレスなど個人情報✉️
Step 3:スナップショット生成関数を作る(考え方)🧠
export function snapshotAuthor(u: UserPublic) {
return {
authorId: u.uid,
authorDisplayName: u.displayName,
authorPhotoURL: u.photoURL,
};
}
記事作成時に、users/{uid} を1回読んで、このスナップショットを posts に入れる…という発想です😄
6) “複製したデータ”はどう整合性を保つ?3つの方針 🧯
ここが第6章の山場です⛰️🔥
方針①:スナップショットで割り切る(おすすめ多め)📸✨
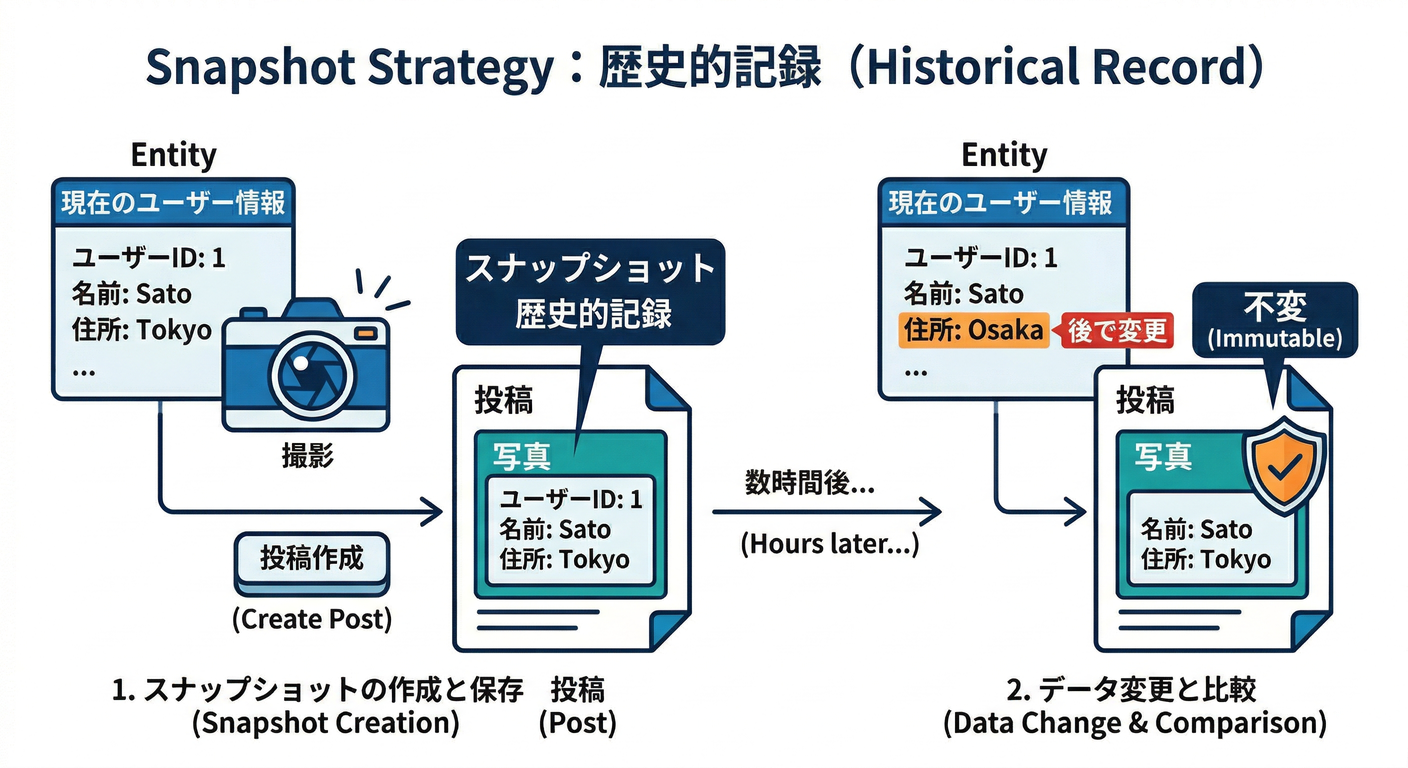
- 「投稿時点の名前が残ってもOK」とする
- SNS/ブログ系だと普通にアリ(むしろ“当時の表示名”が残るのが自然なことも)
👍実装が軽い 👍更新地獄にならない 👎最新名に揃わない
方針②:一部だけ同期する(現実解)🧩
- たとえば「直近30日分の投稿だけ更新」とか
- あるいは「プロフィール画面では最新名」「過去投稿はスナップショット」みたいなハイブリッド
👍ほどよく現実的 👎ルールを決めないとブレる
方針③:全部同期する(強いけど重い)🦾
- ユーザー名が変わったら、過去の
posts/commentsの複製も更新 - これをやるなら **原子性(まとめて成功/失敗)**や、途中失敗時のリカバリ設計が大事
Firestoreには トランザクション / バッチ書き込みがあって、複数ドキュメントを「全部成功 or 全部失敗」にできます(Firebase) ただし大きな更新は詰まりやすいので、どのみち“分割・再実行”の設計が必要になりがちです😇
ちなみに昔よく言われた「1回で500書き込みまで」みたいな話、Firestoreは過去に制限があったけど、リリースノート上では“書き込み数制限を撤廃した”変更が明記されています(ただし他の制限は残ります)(Google Cloud Documentation) → だからこそ「じゃあ無限に更新してOK!」ではなく、運用として安全な更新戦略が重要になります🧯
7) 非正規化するときの“地雷”3つ 💣(ここ大事!)
地雷①:複製が増えるほど、更新時のインデックス更新も増える📈
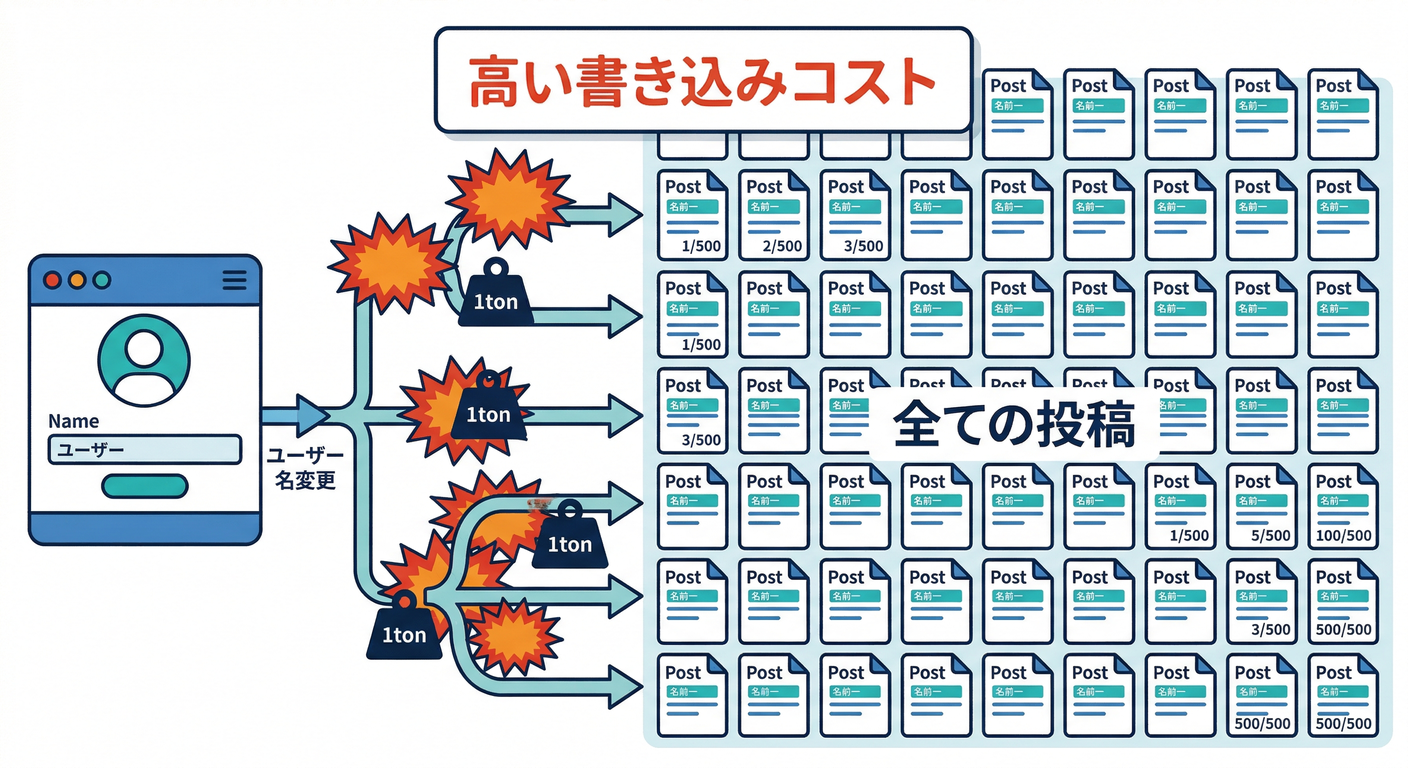
Firestoreの書き込みはインデックス更新も伴うので、**「何も考えずに複製しまくる」**は地味に効きます(Google Cloud Documentation)
👉対策:**検索に使わないフィールドは“インデックスしない”**も検討(特に長文など)🧹 (Firestore側の説明でも、不要なインデックスを止める話が出ます)(Google Cloud Documentation)
地雷②:連番っぽい書き込み集中(ホットスポット)🔥
単調増加する値に対して書き込みが集中するケースは注意、と公式のベストプラクティスでも触れられています(Firebase) (カウンタやランキング系は次章以降でガッツリやります🥇)
地雷③:ドキュメント肥大化(1 MiB)🐘
複製を増やすほど、ドキュメントが太って上限に近づきます🚧(Firebase) 👉対策:表示に必要な最小セットだけ複製、画像はURLだけ、長文は別ドキュメントへ…などが王道です👍
8) ミニ課題:あなたの“複製ライン”を文章で宣言しよう 📝✨
次を埋めてください👇(短くてOK!)
-
記事(posts)に複製する投稿者情報:
- 例:
displayName,photoURL✅
- 例:
-
コメント(comments)に複製する投稿者情報:
- 例:
displayNameだけ / もしくは同じ ✅
- 例:
-
同期方針:
- 例:「スナップショットで割り切る」 or 「直近だけ更新」
-
インデックスしない候補フィールド:
- 例:
authorPhotoURLは検索しないので除外検討、など
- 例:
9) チェック:ここまでできたら勝ち✅🏆
- 「一覧で何回読むか」から、複製の必要性を説明できる📜
- 「変わりやすい値は複製が地獄になりうる」を理解した🔁
- “スナップショットで割り切る”という選択肢が腹落ちした📸
- 複製を増やすと 書き込み+インデックス更新も増える感覚がある🧾(Google Cloud Documentation)
- ドキュメント上限(1 MiB)を意識して、複製の最小化を考えた🐘(Firebase)
10) AIで設計が爆速になる使い方 🤖⚡(Antigravity / Gemini CLI / Firebase AI Logic)
Antigravity:設計レビューを“エージェントに丸投げ”する🛰️
Antigravityは「複数エージェントを管理して、計画→実行」まで寄せる思想の開発環境として紹介されています(Google Codelabs)
投げる指示(コピペ用)📎
- 「日報/記事/コメントをFirestoreで設計。正規化案と非正規化案を2つ作って、読み回数と更新コストの観点で比較して」
- 「投稿一覧の表示を最優先に、複製すべきフィールドと“複製しない方がいいフィールド”を仕分けして」
さらに、FirebaseのMCPサーバーをAntigravityに組み合わせて開発を加速する話も公式ブログで触れられています(The Firebase Blog)
Gemini CLI:ターミナルで“設計→コード雛形”を生成する⌨️✨
Gemini CLIは「ターミナル上のオープンソースAIエージェント」として案内されています(Google for Developers) (ReActループやMCPの話も公式ドキュメント側にあります)(Google for Developers)
投げる指示(コピペ用)📎
- 「PostDoc/UserPublicのTS型と、snapshot関数と、Reactで一覧表示する最小コードを作って」
- 「複製フィールドが増えたときの“インデックス除外候補”を列挙して理由もつけて」
Firebase AI Logic:アプリ内に“設計レビュー機能”を持ち込む🧠📲
Firebase AI Logicは、アプリからGemini/Imagenなどのモデルを使う導線として公式に案内されています(Firebase)
この章でのおすすめ使い方👇
-
管理画面に「設計レビュー」ボタンを置く
-
現在のスキーマ案(JSON)と「想定クエリ一覧」をAIに渡して
- ✅ 非正規化すべき箇所
- ✅ 同期が必要な複製フィールド
- ✅ インデックス除外候補 を提案させる
-
結果を
aiReviewsコレクションに保存して、設計の意思決定ログにする🗂️✨
次章予告👀➡️
次の第7章は、**参照の持ち方(文字列ID vs DocumentReference)**です🔗 第6章で決めた「複製ライン」を、参照設計とセットでさらにカチッと固めます💪✨