第4章:サブコレクションの使いどころ(親子関係に強い)🧩
この章のゴールは、「親子でぶら下がる大量データはサブコレが強い」を体感しつつ、トップレベル案との比較まで自分でできるようになることです💪✨
(題材:posts と comments)
1) まず結論:サブコレがハマる“3つの型”🧠✨
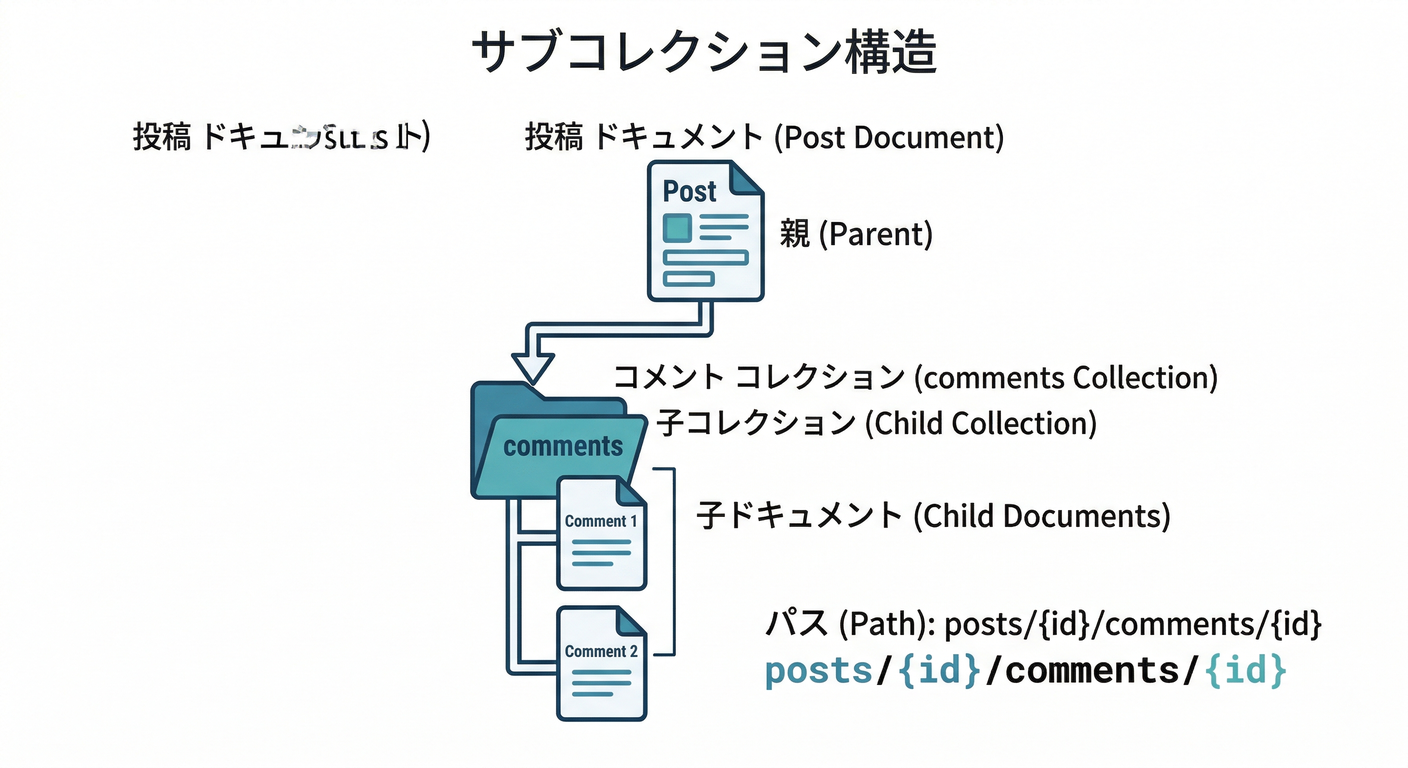
Firestoreはドキュメントの中にサブコレクションを持てます。つまり、posts/{postId}/comments/{commentId} みたいな階層でデータを置けるんだね📚 (Firebase)
サブコレが特に強いのはこの3つ👇
A. 「親が決まってる時だけ読む」データ🧩
例:記事詳細ページでだけ表示するコメント欄
- 画面が
postIdを持ってる(親が分かってる) - だから
posts/{postId}/commentsに“寄せる”と迷子になりにくい🙂
B. 「増え続ける」データ📈
コメント・履歴ログ・通知・監査ログ…みたいに、将来どんどん増えるやつ。 Firestoreの公式ドキュメントでも「時間とともに増えうるデータは、ドキュメント内の配列に詰めるより“コレクション(サブコレ)にする”」方向が語られてます。(Google Cloud Documentation) (ドキュメントは最大 1 MiB なので、配列に詰め込みすぎるといつか破裂する💥)(Google Cloud Documentation)
C. 「親の権限で守りたい」データ🔐
サブコレはパスが親を含むから、Rulesや設計上の見通しが良くなりがち。 「このコメントはどの投稿のもの?」がパスだけで明確になるのは運用で効きます👌
2) 逆に、トップレベルが向く“2つの型”⚖️
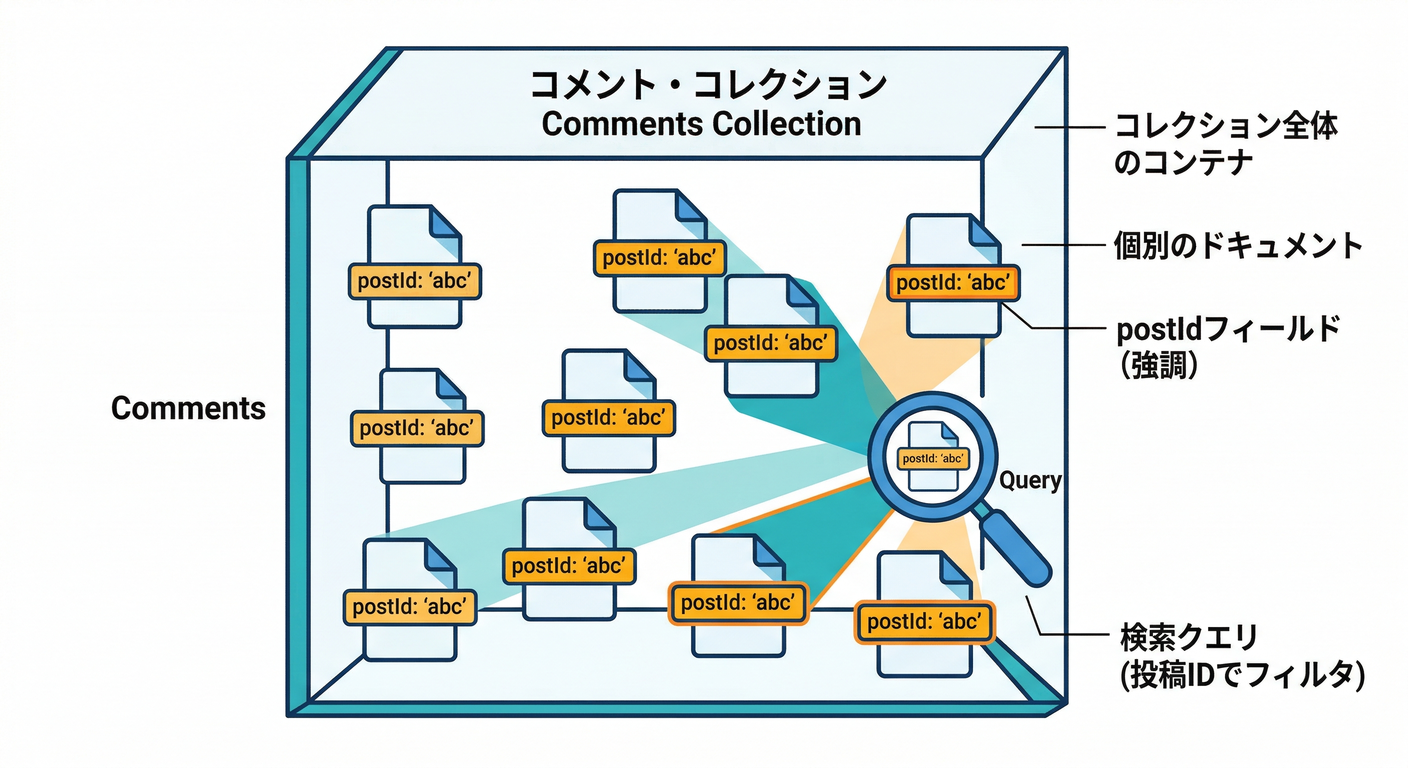
サブコレ万能じゃない!ここ大事🙂
A. “横断検索”が頻発するならトップレベルがラク🔎
例:
- 「自分が書いたコメント一覧」
- 「炎上してるコメントだけ一覧」
- 「全文検索(別サービス連携)用にコメントをまとめて流したい」
こういうのが主役なら comments をトップレベルにして、postId をフィールドで持つ方がシンプルになりがち。
B. “削除・移動・集計”の運用が重いなら注意⚠️
サブコレは「親を消したら子も消える」みたいなカスケード削除はされません。 公式にも「ドキュメント削除してもサブコレは自動削除されない」って明記があります😇 (Firebase) (この爆弾💣は次章でちゃんと処理するよ!)
3) 今回の題材:コメントは “サブコレ案 vs トップレベル案” どっち?🤔🧩
案1:サブコレ(王道)🧩
posts/{postId}posts/{postId}/comments/{commentId}
強いところ
- 設計が直感的(投稿にコメントがぶら下がる)
- 投稿詳細画面の実装が素直
- 将来増えるコメントを配列で抱えずに済む(1MiB回避)(Google Cloud Documentation)
気をつけるところ
- 横断検索は「コレクショングループ」を使う前提になる
- インデックス管理がちょい増える
案2:トップレベル(検索に強い)📚
posts/{postId}comments/{commentId}(フィールドにpostIdを入れる)
強いところ
- どんな一覧もクエリが作りやすい(
where("postId","==",...)等) - データ移動・管理の運用が単純になりやすい
気をつけるところ
- 「このコメントは投稿に属する」という構造がパスから消える
- Rulesや運用で “postId の整合性” をちゃんと守る必要が増える
4) サブコレでも“横断検索”はできる:コレクショングループ🧩🔎
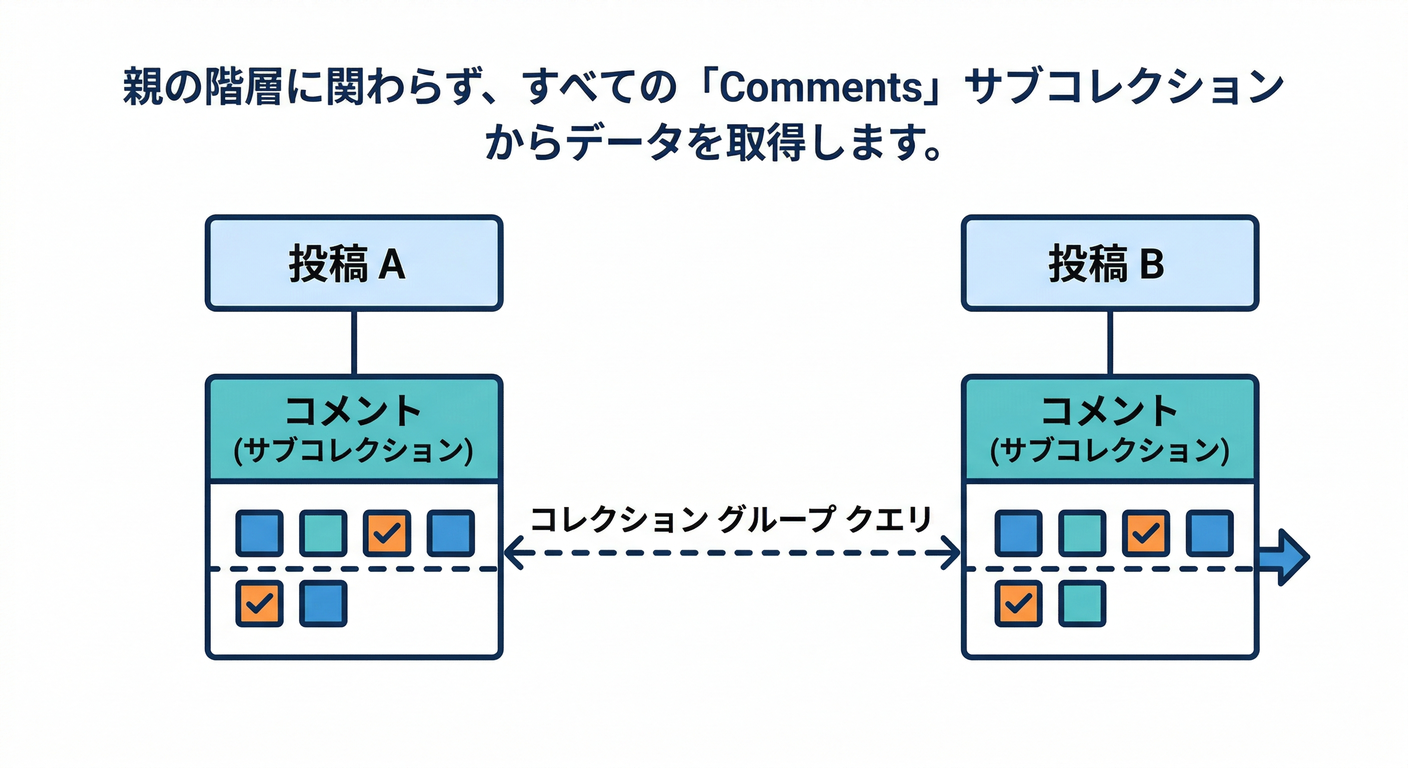
サブコレを採用しても、同じ名前(例:全部 comments)なら collection group query で横断検索できます✨ (Firebase)
ただし!
フィルタや orderBy を使うコレクショングループは、collection group スコープのインデックスが必要になることがあります。(Firebase)
(足りないとエラーが出て、コンソール/CLIで作る流れになるやつ🛠️)
5) 手を動かす:2案のクエリを“同じ要件”で書いてみよう✍️⚡
ここでは「同じUI要件」を想定して、クエリの書きやすさを比較するよ🙂
要件(超よくある)📱
- 投稿詳細でコメント一覧(新しい順)
- 「自分のコメント一覧」
- 迷惑コメントだけ一覧(moderationFlag=true)
5-1) サブコレ案のクエリ例🧩
import { collection, collectionGroup, getFirestore, limit, orderBy, query, where } from "firebase/firestore";
const db = getFirestore();
// 1) 投稿詳細:その投稿のコメント一覧(新しい順)
function qCommentsOfPost(postId: string) {
return query(
collection(db, "posts", postId, "comments"),
orderBy("createdAt", "desc"),
limit(50)
);
}
// 2) 自分のコメント一覧(横断)※collection group
function qMyComments(uid: string) {
return query(
collectionGroup(db, "comments"),
where("authorId", "==", uid),
orderBy("createdAt", "desc"),
limit(50)
);
}
// 3) 迷惑コメントだけ(横断)※collection group
function qFlaggedComments() {
return query(
collectionGroup(db, "comments"),
where("moderationFlag", "==", true),
orderBy("createdAt", "desc"),
limit(50)
);
}
ポイント👉
- 投稿詳細はめちゃ素直👍
- 横断系は
collectionGroup(db, "comments")が主役になる🙂 - フィルタ+ソートはインデックスが要ることがある(エラーが先生)(Firebase)
5-2) トップレベル案のクエリ例📚
import { collection, getFirestore, limit, orderBy, query, where } from "firebase/firestore";
const db = getFirestore();
// comments/{commentId} に postId を持つ前提
function qCommentsOfPost(postId: string) {
return query(
collection(db, "comments"),
where("postId", "==", postId),
orderBy("createdAt", "desc"),
limit(50)
);
}
function qMyComments(uid: string) {
return query(
collection(db, "comments"),
where("authorId", "==", uid),
orderBy("createdAt", "desc"),
limit(50)
);
}
function qFlaggedComments() {
return query(
collection(db, "comments"),
where("moderationFlag", "==", true),
orderBy("createdAt", "desc"),
limit(50)
);
}
ポイント👉
- 横断検索が最初から素直!
- その代わり、**「このコメントはこの投稿に属する」**を
postIdで守り続ける設計が必要になる(改ざん対策も含む)🔐
6) ミニ課題:あなたのアプリならどっち?📝🔥
次の質問に“自分の言葉”で答えてみてね👇
-
コメントは「投稿詳細で読む」が9割?それとも「コメント一覧」が主役?📱
-
「自分のコメント一覧」「通報コメント一覧」を最初から作る?🔎
-
投稿削除の時、コメントはどう扱いたい?(残す/消す/凍結)🧊💥
-
AIでコメントを要約・判定するなら、結果はどこに置く?🤖
- 例:コメントdocに
moderationFlagを持つ - 例:
posts/{postId}/comments/{commentId}/aiReviews/{reviewId}に履歴として残す(後で監査しやすい)
- 例:コメントdocに
7) AIで“設計の迷い”を秒速で減らす🤖⚡(Antigravity / Gemini CLI)
Googleの Antigravity は「エージェントが計画→調査→実行」みたいに動くIDEコンセプトのCodelabが出ています。(Google Codelabs) Gemini CLI はターミナルで動くオープンソースのAIエージェントで、ReActループで作業を進める説明があります。(Google for Developers)
コピペで使える依頼文📎✨
-
サブコレ案 vs トップレベル案を比較して!
- 「
postsとcommentsを、サブコレ案とトップレベル案で2案作って。各案で“必要なクエリ3つ(投稿コメント/自分のコメント/通報一覧)”と“必要そうなインデックス”も列挙して。運用リスク(削除/集計/改ざん)も比較して。」
- 「
-
コレクショングループのインデックス当たりを付けて!
- 「
collectionGroup('comments')でwhere(authorId==)とorderBy(createdAt desc)を使う時、必要になるインデックスの考え方を説明して。エラーが出た時の読み方も。」
- 「
-
AI結果をFirestoreに残す設計レビューして!
- 「コメントのモデレーション結果をFirestoreに保存したい。履歴を残す設計(監査ログ)と、最新だけ持つ設計を比較して。個人情報・コスト・改ざん耐性も見て。」
※ AIをアプリに入れるときは App Check と レート制限が重要になってくるよ(Firebase AI Logic側でデフォルト “1ユーザー100RPM” などの話がある)(Firebase) このへんは「ログ設計」や「誰が叩けるか」の形に直結する🔥
8) チェック(この章で“できたら勝ち”✅)
- 「サブコレが向く場面」を3つ言える🧩
- 「トップレベルが向く場面」を2つ言える⚖️
- サブコレでも
collectionGroupで横断検索できるのを理解した🔎 (Firebase) - 親を消しても子が消えないことを知った(次章の地雷💣)(Firebase)
次の第5章は、ここで出した地雷――削除・移動・集計で「サブコレが詰まりやすいポイント」を、ちゃんと安全策つきで片付けるよ💥🧯