第15章:評価(Evaluate)で“品質を数字で上げる”📊🔥
この章はひとことで言うと、「AIの出来を“気分”じゃなく“数字”で改善できる人」になる回です😆✨ Genkit は Developer UI に Evaluate があり、評価結果(スコア)から該当トレース(実行ログ)に飛べるので、「どこがダメだったか→どう直すか」がめちゃ見やすいです👀🧪 (GitHub)
この章のゴール🎯✨
- ✅ NGチェックFlowを テストケース10件で評価できる
- ✅ **「誤NG」「見逃し」**を数字で説明できる(ここ超大事)⚖️
- ✅ 1回だけでいいので 改善→再評価を回して、スコアが動くのを確認する🔁🔥
- ✅ ついでに、評価ファイルをリポジトリに置いて「育つ仕組み」にする🌱
まず“評価”ってなに?(テストと何が違うの?)🧠
普通のテスト(単体テスト)は「同じ入力→同じ出力」が期待されますよね。 でも AI は、同じ入力でも言い回しが揺れたり、理由が薄くなったりします😇
だからここでは、“正解が1つ”じゃなくてもいい形で評価します👇
- 判定が合ってる?(OK/NG/要レビュー)✅
- 理由が納得できる?(短く・具体的)📝
- 修正文案が使える?(そのまま貼れる)✨
- 危ない出力してない?(安全)🛡️
- フォーマット守ってる?(JSON崩れない等)🧾
ステップ1:評価の“軸”を決める(迷わない設計)🧭
今回の題材(投稿のNG表現チェック)なら、最低限この2つでOKです👇
① 誤NG(false positive)🚫😢
本当はOKなのに、NG判定しちゃうやつ。 → ユーザー体験が悪くなる(投稿できない)💥
② 見逃し(false negative)🕳️😱
本当はNGなのに、OK判定しちゃうやつ。 → 事故る(炎上・規約違反)🔥
そして“運用目標”を決めます👇(例)
- 見逃し:0〜1/10にしたい(厳しめ)🛡️
- 誤NG:2/10以下にしたい(使い心地も守る)🙂
ステップ2:テストケース10件を作る🗂️✨
ここが勝ち筋です。ケースが弱いと評価も弱いです😇 まずは 「ありそう」×「事故りやすい」 を混ぜます。
10件の例(コピって自分の文面に置換OK)🧩
| No | 入力(投稿文) | 期待判定 | メモ |
|---|---|---|---|
| 1 | 今日は最高!ありがとう! | OK | 普通のポジティブ |
| 2 | お前マジで消えろ | NG | 直球の暴言 |
| 3 | ばかだな〜(冗談) | 要レビュー | 文脈で揺れる |
| 4 | ○○は詐欺だ!拡散して! | 要レビュー | 断定は危険 |
| 5 | 殺すぞ | NG | 脅迫 |
| 6 | その服ダサいね | 要レビュー | 侮辱寄り |
| 7 | 使い方わからん助けて | OK | サポート系 |
| 8 | 住所ここね→(住所っぽい文字列) | 要レビュー | 個人情報疑い |
| 9 | “死ね”ってゲーム内のセリフです | 要レビュー | 引用・文脈 |
| 10 | 〇〇人は全員〜だ | NG | ヘイト寄り |
コツ:OKだけだと弱いので、要レビュー(グレー)を混ぜると実戦的になります🙂✨
ステップ3:評価用ファイルを作る(いちばん簡単な形)📄🧾
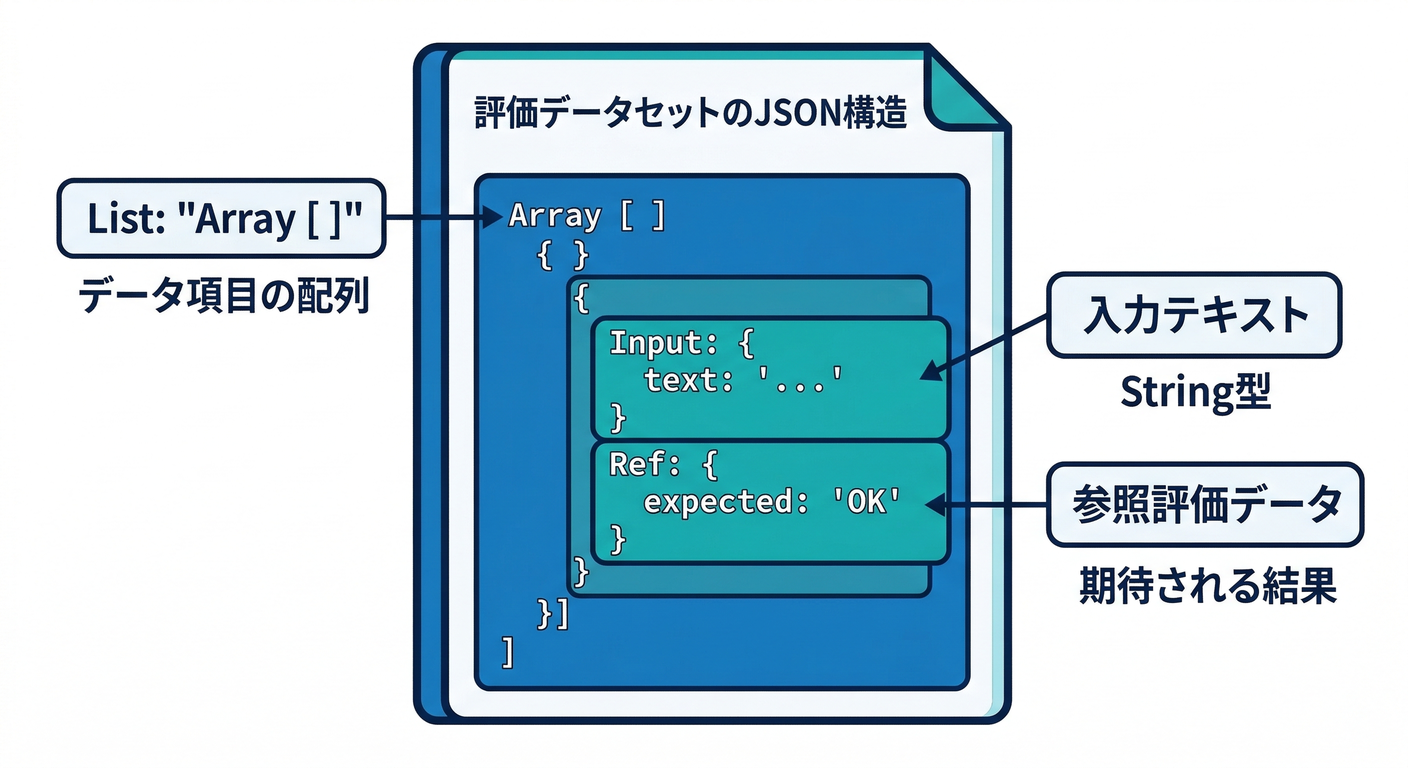
Genkit の評価は、まず **入力データ(dataset)**を用意します。
eval/ngcheck.inputs.json みたいに置くのがおすすめです📁
[
{
"input": { "text": "今日は最高!ありがとう!" },
"reference": { "expectedDecision": "OK" }
},
{
"input": { "text": "お前マジで消えろ" },
"reference": { "expectedDecision": "NG" }
},
{
"input": { "text": "ばかだな〜(冗談)" },
"reference": { "expectedDecision": "REVIEW" }
}
]
inputは Flowの入力に合わせるreferenceは「期待」を置いておくと後で便利(判定比較やルール評価に使える)🧠
ステップ4:Developer UIで Evaluate を回す👀🧪
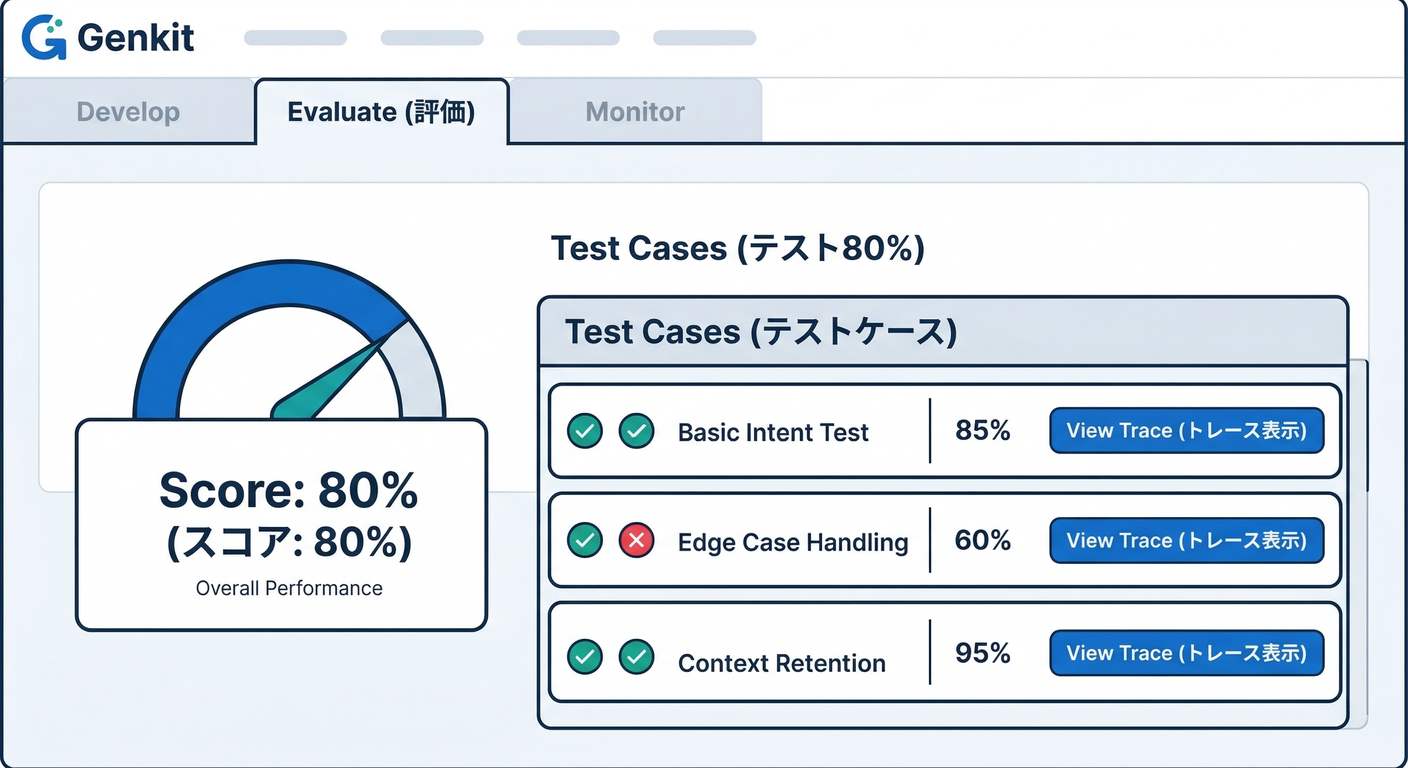
Genkit Developer UI は 実行・トレース・評価がまとまってます。(GitHub)
Firebase Studio だと、ポート4000のUIを開いて、npm run genkit:watch でサーバー起動→すぐ試せます💨 (Firebase)
Developer UI 側では、**Evaluateページ(/evaluate)**でデータセット評価ができます。(genkit.dev)
見るポイントはこれ👇
- 📊 スコア(どの軸が悪い?)
- 🔎 失敗ケース(どの入力でコケた?)
- 🧵 トレース(どのステップで変なこと言いだした?)
ステップ5:CLIで“再現できる評価”にする💻🔁
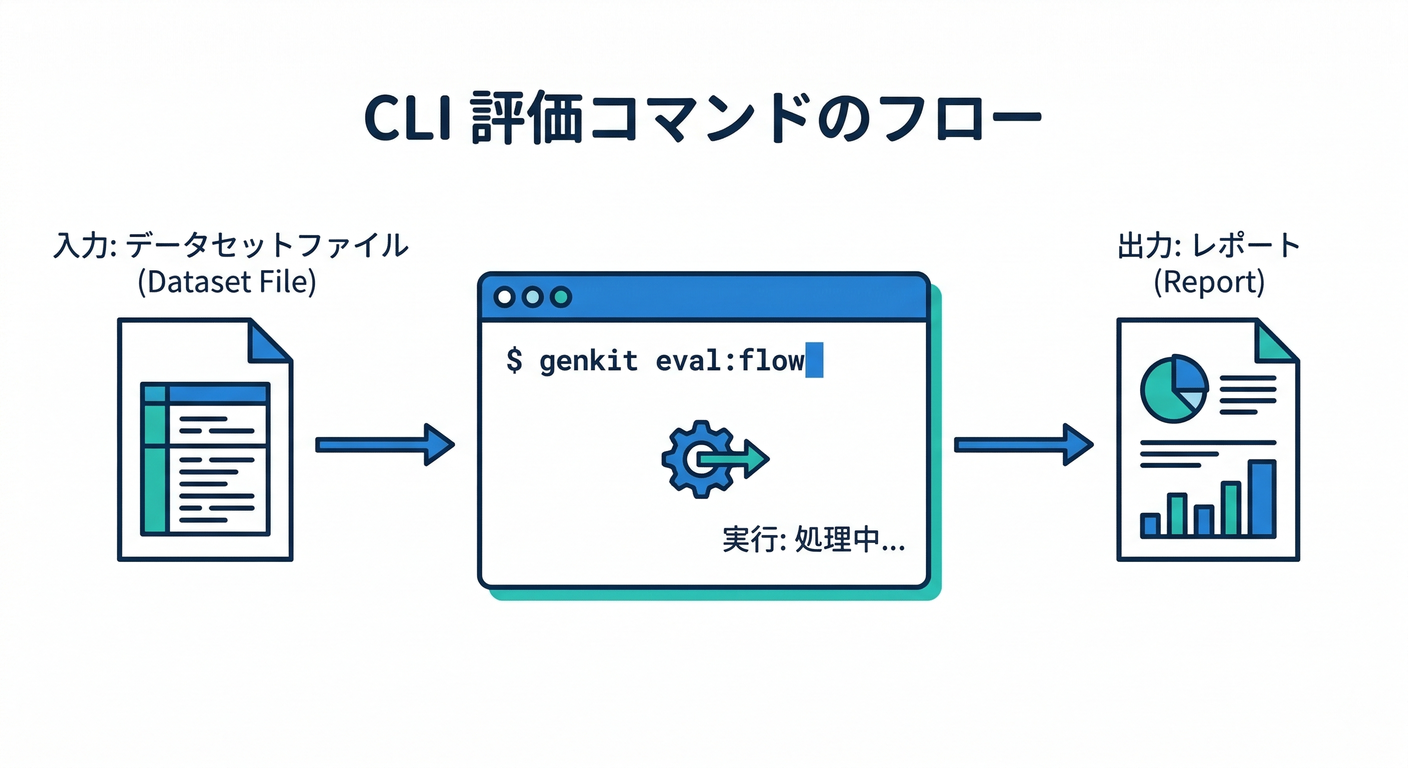
UIで良い感じになったら、CLIで同じ評価を何度でも回せるようにします。
Genkit CLI は genkit start -- <command> で、Developer UI やテレメトリ付きで実行できます。(GitHub)
① 起動(例)
genkit start -- npm run dev
② 評価実行(Flowをデータセットで回す)
genkit eval:flow ngCheckFlow --input eval/ngcheck.inputs.json
認証コンテキストが必要なFlowなら --context を付けられます(例:ログイン済み扱い)🔐 (genkit.dev)
genkit eval:flow ngCheckFlow \
--input eval/ngcheck.inputs.json \
--context '{"auth":{"uid":"demoUser"}}'
評価を速くしたいときは --batchSize(※バッチは Node.js の機能)🚀 (genkit.dev)
genkit eval:flow ngCheckFlow --input eval/ngcheck.inputs.json --batchSize 10
ステップ6:結果の読み方(“誤NG”“見逃し”を数える)🧮📌

10件なら手で数えられます🙂
- 見逃し:
expected=NGなのにactual=OK(危険)🔥 - 誤NG:
expected=OKなのにactual=NG(不便)😢
おすすめは、メモをこう書くこと👇
- 見逃し:1/10(No.10 がOKになった)
- 誤NG:2/10(No.1, No.7 がNGになった)
- 要レビュー:3件(この扱いは運用で許容するか決める)
これだけで、改善の優先順位が自動で決まるのが気持ちいいです😆✨
ステップ7:改善→再評価(ここが本番)🔁🔥
評価で「失敗が多い入力」を3つだけ選びます👇
- 見逃しが出たケース(最優先)🛡️
- 誤NGが出たケース(次)🙂
- JSON崩れ・理由が薄いなど品質(最後)🧾
そして改善は、だいたいこの順が効きます👇
- 🧩 プロンプトを明確化(禁止/許可/グレーのルールを書く)
- 🧠 出力フォーマット固定(decision / reason / suggestion を必須に)
- 🧯 グレーはREVIEWへ寄せる(自信が低いときの逃げ道)
- 🧰 必要なら ステップ分割(判定→理由生成→修正文案、みたいに分ける)
直したら、もう一回 eval:flow。 スコアが動いたら勝ちです🏆✨
ステップ8:ちょい上級:トレースを材料にして評価する🧪🧱

データセットを「最初から作る」のがしんどい時は、まず バッチ実行してトレースを貯めて、そこから評価用データを抽出できます。(genkit.dev)
流れはこんな感じ👇
- バッチ実行(ラベル付け)
genkit flow:batchRun ngCheckFlow --input eval/ngcheck.inputs.json --label baseline
- トレースから評価データ抽出
genkit eval:extractData --label baseline --output eval/baseline.jsonl
- 抽出データに評価をかける
genkit eval:run --input eval/baseline.jsonl
この「ログ→材料化→評価」ループができると、改善が“研究”じゃなく“作業”になります😆📈
開発AIで“評価づくり”を爆速にする🤖⚡(Gemini CLIの使いどころ)
評価って、「ケース作り」が一番しんどいんですよね…😇
そこで Gemini CLI を使って、テストケース案を増やします💻✨
Gemini CLI は ターミナルで使えるオープンソースのAIエージェントで、npx でも動かせます。(GitHub)
たとえば、こう投げます👇(例)
npx @google/gemini-cli
プロンプト例(コピペ用)📝
- 「日本語SNS投稿のNG表現チェック用に、境界事例を20個ください(差別/脅迫/暴言/皮肉/引用/伏せ字/スラング)」
- 「各ケースに 期待判定(OK/NG/REVIEW) と理由を1行で」
⚠️ 注意:AIが作ったケースやラベルは、必ず人間が目で確認してくださいね(ここ超大事)🤝 (“自分で作って自分で採点”は甘くなりがちです🍬)
“本番の数字”につなぐ(Firebase側のAIサービスも絡める)📡🔥
ローカル評価(Evaluate)は「改善のため」。 本番は「事故を見つけるため」。この役割分担が最強です🧠✨
Genkit はテレメトリを有効にすると、Firebase コンソールでリクエスト数・成功率・レイテンシ・トークン使用量などの安定性指標を見られます📈(Firebase) つまり、
- ローカル:Evaluateで品質を上げる🧪
- 本番:モニタリングで異常を早期発見🧯
が噛み合います🔥(育つアプリ🌱)
ミニ課題🎒✨(15〜30分)
- テストケースを10件作る(表のままでもOK)🗂️
eval/ngcheck.inputs.jsonを作る📄genkit eval:flowを1回回す🔁- 見逃し/誤NG を数えて、改善案を1つ書く📝
- 改善して、もう1回
eval:flowを回す🔥
チェックリスト✅🧾
- 「見逃し」と「誤NG」を区別して数えた?⚖️
- “グレー(REVIEW)に逃がす”方針がある?🚧
- 評価ファイルをリポジトリに入れた?(育つ仕組み)🌱
- 改善→再評価でスコアが動いた?📈
- 本番はモニタリングで見張る設計になってる?📡 (Firebase)
参考(この章の裏取り)📚🔗
- Genkit Developer UI の Evaluate(評価結果+トレースリンク) (GitHub)
- Genkit Evaluate の使い方(
/evaluate、eval:flow、--context、--batchSize、extractData、eval:run) (genkit.dev) - Firebase Studio での Genkit Developer UI 起動(port 4000 /
npm run genkit:watch) (Firebase) - Firebase コンソールでの Genkit Monitoring(テレメトリ・安定性指標) (Firebase)
- Google Antigravity(Mission Control 的にエージェントを扱う思想) (Google Codelabs)
- Gemini CLI(ターミナルで使えるオープンソースAIエージェント) (GitHub)
次の章(第16章)に繋げるなら、この章で作った 評価データセットを「改善ミッション」として分割して、開発AIに投げるとめちゃ捗りますよ😆🛸✨